rclone同步文件到Google云盘
安装unzip
rclone安装用的到unzip
apt install -y unzip
安装fuse3
apt install -y fuse3
安装socat (可选)
socat 用于后续配置的时候, 代理127.0.0.1上的端口.也可以用其他代理工具代理
apt install -y socat
安装rclone
curl https://rclone.org/install.sh | sudo bash
创建本地文件夹,用于同步远程
mkdir -p /google_drive_local
配置
rclone config
注意是 google drive,不是 google cloud 或 google photos
socat代理端口
配置的过程中, 会等待回调http:127.0.0.1:xxxx这样的端口 由于Linux上没有安装桌面端,需要代理出来,在桌面端浏览器访问
如下,将服务器上的127.0.0.1的xxxx端口映射到Linux公网IP上的1234端口
#如 控制台这样提示的时候, 使用下面命令 2024/05/10 01:38:21 NOTICE: If your browser doesn't open automatically go to the following link: http://127.0.0.1:53682/auth?state=Czs9IR66wt5eLQYQtlogbQ
socat TCP-LISTEN:1234,fork,reuseaddr TCP:127.0.0.1:53682
代理成功后, 在桌面端浏览器访问, 访问完成,授权登录后,Linux终端会提示Success,即完成了配置
创建Service, 启动挂载
需要特别注意的是: rclone mount 每次挂载后,总是用云盘的数据覆盖本地的挂载文件夹, 所以云盘上不存在,但是存在于本地挂载文件夹/google_drive_local下的数据一定要先做备份,避免覆盖丢失
vim /etc/systemd/system/rclone-mount.service 文件内容如下
[Unit]
Description=RClone Mount Service
After=network-online.target
[Service]
User=root
Group=root
ExecStart=/usr/bin/rclone mount google_drive:/vps_backup/xjp /google_drive_local --allow-other --allow-non-empty --vfs-cache-mode writes
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
重新加载 systemd 并启动服务
sudo systemctl daemon-reload
sudo systemctl start rclone-mount.service
sudo systemctl enable rclone-mount.service
创建备份脚本
vim /usr/local/bin/vps_backup 内容如下
cd / && tar -zcvf app.tar.gz /app/ && mv app.tar.gz /google_drive_local/
赋予执行权限chmod +x /usr/local/bin/vps_backup
编写定时任务
执行crontab -e打开定时任务配置文件,
增加以下内容
#12小时同步一次
0 */12 * * * /usr/local/bin/vps_backup
#30分钟执行一次
*/30 * * * * /usr/local/bin/vps_backup
查看所有的rclone配置
rclone config show
docker-compose网络
docker-compose网络
网段隔离
在不同的文件下存放docker-compose.yml, 如mysql/docker-compose.yml, redis/docker-compose.yml, 当执行docker-compose up -d会自动创建一个新的网络. 通过docker network ls可以看到. 每一个网络相互隔离.
root@ec2-0804:# docker network ls
NETWORK ID NAME DRIVER SCOPE
8fbc5468dcab bridge bridge local
46e3affd9d7c host host local
e778a30f25d4 mysql_default bridge local
3b2337441be6 vaultwarden_default bridge local
网段打通
有时候, 并不想隔离, 比如zk和kafka共享一个网络. 比如应用微服务和mysql共享同一个网络
方法一
nginx和kafka存放在同一个nginx\docker-compose.yml中,启动后自然就是同一个网络. 如
version: '3.8'
services:
nginx:
image: zookeeper
container_name: nginx
vaultwarden:
image: vaultwarden/server:latest
container_name: vaultwarden
启动后, 会创建一个新的网络nginx_default,前缀来自于当前docker-compose.yml所在的文件夹的名字
方法二
手动创建一个网络
docker network create --driver=bridge --subnet=172.16.238.0/24 --gateway=172.16.238.1 my_docker_network
在不同的docker-compose.yml中指定想要加入的网络
version: '3.8'
services:
vaultwarden:
image: vaultwarden/server:latest
container_name: vaultwarden
restart: always
environment:
#
- WEBSOCKET_ENABLED=true
# 禁止邀请
- INVITATIONS_ALLOWED=false
# 禁止注册. 注意, 初始化搭建的时候.需要改成true,启动后注册用户.注册成功后,改成false,重新执行docker-compose up -d
- SIGNUPS_ALLOWED=false
- ADMIN_TOKEN=AqaiTTm4LbMaTCyVFLTFzwmHPxxYa4Kg
volumes:
- /app/docker/vaultwarden/data:/data/
#ports:
# 由于vaultwarden和nginx部署在了同一个网络下,所以用服务名通信了.因此不需要暴漏80端口
#- "80:80"
networks:
- my_docker_network
networks:
my_docker_network:
external: true
docker常用操作记录
容器中执行apt update报错
解决办法
sed -i 's/stretch/buster/g' /etc/apt/sources.list
查看指定容器的近10条日志
docker logs --tail 10 -f mariadb1
docker指定常用参数
- 指定网络
- 指定ipv4地址
- 绑定hosts
version: '3.8'
services:
nginx:
image: nginx:1.21.1
container_name: nginx
restart: always
ports:
- 80:80
- 443:443
volumes:
- /app/docker/nginx/nginx:/etc/nginx
- /root/.acme.sh/*.nguone.eu.org_ecc/fullchain.cer:/etc/nginx/ssl/vaultwarden.crt:ro
- /root/.acme.sh/*.nguone.eu.org_ecc/*.nguone.eu.org.key:/etc/nginx/ssl/vaultwarden.key:ro
extra_hosts:
- "remotework.nguone.eu.org:172.31.5.162"
networks:
my_docker_network:
ipv4_address: 172.16.238.6
networks:
my_docker_network:
external: true
docker gitea搭建
配置Nginx
git.conf
server {
listen 80; #侦听80端口,如果强制所有的访问都必须是HTTPs的,这行需要注销掉
listen 443 ssl;
server_name git.xxx.com;
ssl_certificate /root/.acme.sh/*.xxx.com_ecc/fullchain.cer;
ssl_certificate_key /root/.acme.sh/*.xxx.com_ecc/*.xxx.com.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
client_max_body_size 1024m;
# 开启HSTS后能够提升到A+. SSL评估 https://myssl.com/
add_header Strict-Transport-Security "max-age=31536000";
location / {
proxy_set_header HOST $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://127.0.0.1:3000;
}
}
Nginx配置重载
nginx -s reload
docker-compose.yml
version: '3.8'
services:
gitea:
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/gitea/gitea:1.22.3
container_name: gitea
environment:
- USER_UID=1000
- USER_GID=1000
- DB_TYPE=sqlite3
restart: always
volumes:
- ./data:/data
ports:
- "3000:3000" # Gitea 的 Web UI 端口,也是通过http 克隆项目的端口
- "2222:22" # 如果这里使用22端口. 拉取项目的时候可以省去端口号.因为通过ssh key clone项目用的是22端口
启动
需要注意的时候, git要使用22端口.默认情况下22端口被宿主机的ssh占用.所以需要修改宿主机下的Port 22 为其他端口, 修改后切记放行新的ssh端口,防止无法ssh .
systemctl resetart sshd重新启动sshd
docker-compose up -d
特别注意
如果启动后访问 https://git.xxx.com, 自动跳转到其他的域名,可能的解决方案是:
编辑 /etc/nginx/sites-available/default
直接注释掉
server_name _;然后重载Nginx配置
启动成功后,访问http://宿主机IP:3000访问web控制台.注册一个管理员
需要注意的是,如果端口改成非22端口了,比如2222.那么初始化安装的时候, [SSH Server Port]要修改ssh端口为2222,而不是默认的22 这里的修改的2222是指以后拉取项目用的端口地址,而不是容器的内部端口,内部端口仍然是22
注册好管理员后, 通过命令行把注册禁用掉
docker exec -it gitea bash
vi /data/gitea/conf/app.ini
# 找到 DISABLE_REGISTRATION, 将值从false,改为true.
修改完后,退出docker容器. 重启gitea docker restart gitea
ssh key clone
gitea 默认使用3071长度的ssh key拉取项目.所以Windows或者Linux默认的2048无法使用.
生成3071长度的密钥
3071 表示 位长的 RSA 密钥
ssh-keygen -t rsa -b 3071
生成之后, 登录gitea web控制台将公钥添加到SSH / GPG Kyes 中 就可以正常clone项目了
补充说明
通过ssh拉取项目
推荐搭建gitea的时候使用22端口
- 使用22端口拉取项目
git clone git@git服务器IP/项目组或者用户名/work-record.git - 使用2222端口拉取项目
git clone ssh://git@git服务器IP:2222/项目组或者用户名/work-record.git
docker anylink搭建
生成web控制台登录密码
nooqu6aifahsh5Ae为web控制台登录密码
docker run -it --rm stilleshan/anylink:0.9.3 tool -p nooqu6aifahsh5Ae
生成 jwt secret
docker run -it --rm stilleshan/anylink:0.9.3 tool -s
docker-compose搭建Nextcloud
docker-compose.yml
version: '3.9'
services:
nextcloud:
image: nextcloud:latest
container_name: nextcloud
ports:
- "8080:80" # 将主机的 8080 端口映射到容器的 80 端口
volumes:
- nextcloud_data:/var/www/html
- ./config/config.php:/var/www/html/config/config.php
environment:
- MYSQL_HOST=mysql5.7.28 # 使用你的 MySQL 容器名称作为主机名
- MYSQL_DATABASE=nextcloud
- MYSQL_USER=nextcloud_user
- MYSQL_PASSWORD=Aphu2jieChie6mo2
networks:
- mysql_default
networks:
mysql_default:
external: true
volumes:
nextcloud_data:
./config/config.php配置
支持HTTPS域名访问,输入自己的域名
'trusted_domains' =>
array (
0 => 'nextcloud.mydomain.xyz',
),
赋予权限
docker exec -it nextcloud bash
chown -R www-data:www-data /var/www/html/config
chmod -R 755 /var/www/html/config
chown www-data:www-data /var/www/html/config/config.php
chmod 644 /var/www/html/config/config.php
然后使用Nginx转发即可, 最后重启Nginx,即可完成https访问.可以参考**Linux常用技巧篇的Nginx https配置**
彻底删除
docker rm -f nextcloud
docker volume ls
docker volume rm nextcloud_data
rm -rf ./nextcloud_data
docker rmi nextcloud:latest
基于阿里云盘webdav实现owncloud双备份
创建目录
mkdir -p /app/docker/aliyundrive-webdav
创建docker-compose.yml
cd /app/docker/aliyundrive-webdav && nano docker-compose.yml
version: '3.8'
services:
aliyundrive-webdav:
image: messense/aliyundrive-webdav
container_name: aliyundrive-webdav
restart: always
# ports:
# - "28080:8080"
environment:
- REFRESH_TOKEN=${REFRESH_TOKEN} # REFRESH_TOKEN写在.env文件中,防止太长的字符串在docker-compose中被截断,注意这里实际上是对应access_token
- WEBDAV_AUTH_USER=这里是webdav的网页登录用户名,自定义
- WEBDAV_AUTH_PASSWORD=这里是webdav的网页登录密码,自定义
env_file:
- .env
.env
nano .env
REFRESH_TOKEN=xxxx改成自己的token
-
参考 :https://github.com/messense/aliyundrive-webdav?tab=readme-ov-file
启动aliyundrive-webdav
docker-compose up -d
通过rclone webdav配置
rclone config
# 按照提示配置。选webdav。密码和密码就是上面配置的
挂载
假如上面配置的阿里云盘名叫aliyun_drive
mkdir /aliyun_drive_local && nohup rclone mount aliyun_drive:/ /aliyun_drive_local --vfs-cache-mode writes >> /tmp/aliyun_drive_local.log 2>&1 &
开机自动挂载
sudo nano /etc/systemd/system/rclone-mount.service
[Unit]
Description=Mount Aliyun Drive with Rclone
After=network-online.target
[Service]
Type=simple
ExecStart=/usr/bin/rclone mount aliyun_drive:/ /aliyun_drive_local --vfs-cache-mode writes
ExecStop=/bin/fusermount -u /aliyun_drive_local
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
sudo systemctl daemon-reload
sudo systemctl restart rclone-mount.service
安装inotify,用于监听owncloud文件变化
sudo apt update
sudo apt install inotify-tools
配置脚本sync_with_inotify.sh
nano /app/sync_with_inotify.sh
通过
inotifywait实现对指定目录的实时监控,一旦检测到文件的创建、修改、删除或移动事件,就会触发rclone sync命令,将本地目录同步到远程存储(如阿里云盘)。它还包含一些优化措施,例如延迟处理、避免重复触发等
#!/bin/bash
LOCAL_DIR="/app/docker/owncloud/owncloud/data/files/admin/files"
LOG_FILE="/tmp/rclone_owncloud.log"
## 使用 inotifywait 监听本地文件夹变化
inotifywait -m -r -e create,modify,delete,move "$LOCAL_DIR" |
while read -r directory events filename; do
echo "Detected $events on $filename"
# 延迟执行,避免频繁触发
sleep 10
# 防止重复同步
if pgrep -f "rclone sync" > /dev/null; then
echo "Sync is already running, skipping this event."
continue
fi
rclone sync "$LOCAL_DIR" aliyun_drive:/owncloud_backup \
--exclude "*.d*" \
--transfers 2 \
--checkers 2 \
--delete-during \
--log-level DEBUG \
--log-file "$LOG_FILE"
done
-
命令解释:
-
-m:开启持续监控模式。 -
-r:递归监听子目录中的变化。 -
-e create,modify,delete,move:监听以下事件:
create:文件或目录的创建。modify:文件内容的修改。delete:文件或目录的删除。move:文件或目录的移动或重命名。
-
"$LOCAL_DIR":指定要监听的目录。
功能:当监控的目录中发生指定的事件时,将事件信息通过管道传递到
while循环中。 -
添加执行权限
chmod +x /app/sync_with_inotify.sh
作为服务启动
sudo nano /etc/systemd/system/sync_with_inotify.service
[Unit]
Description=Sync files with Aliyun Drive using rclone and inotify
After=network.target
[Service]
ExecStart=/bin/bash /app/sync_with_inotify.sh
Restart=always
RestartSec=10s
User=root
WorkingDirectory=/app
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
重新加载 systemd 配置
sudo systemctl daemon-reload
启动并使服务开机启动
sudo systemctl start sync_with_inotify.service
sudo systemctl enable sync_with_inotify.service
sudo systemctl status sync_with_inotify.service
sudo systemctl restart sync_with_inotify.service
sudo systemctl stop sync_with_inotify.service
查看日志
journalctl -u sync_with_inotify.service -f
手动同步
多次同步不影响
rclone sync "/app/docker/owncloud-ok/files/files/" aliyun_drive:/owncloud_backup --exclude "*.d*" --transfers 2 --checkers 2 --delete-during --log-level DEBUG --log-file /app/rclone_owncloud.log
查看日志文件
tail -f /tmp/rclone_owncloud.log
需要将webdav的IP固定
避免重启服务后,IP变化....最终导致rclone中的webdav地址发生变化,无法连接到webdav
不想挂载时,卸载已挂载的文件夹
fusermount -uz /aliyun_drive_local
基于docker-compose安装fail2ban
安装rsyslog
fail2ban依赖rsyslog,安装并启动后,会产生日志文件 /var/log/auth.log
apt update
apt install rsyslog -y
rsyslogd
docker-compose.yml
mkdir -p /app/docker/fail2ban/
cd /app/docker/fail2ban/
cat <<EOF > docker-compose.yml
version: '3.8'
services:
fail2ban:
image: crazymax/fail2ban:latest
container_name: fail2ban
restart: always
network_mode: host
cap_add:
- NET_ADMIN
- NET_RAW
volumes:
- ./data:/data
- /var/log:/var/log:ro
EOF
启动
docker-compose up -d
配置SSH规则
#内容如下
cat <<EOF > data/jail.d/sshd.conf
[sshd]
enabled = true
chain = INPUT
port = ssh
filter = sshd[mode=aggressive]
logpath = /var/log/auth.log
maxretry = 3
findtime = 60 # 1 分钟内
bantime = 31536000 # 封禁 365 天(31,536,000 秒)
EOF
重启启动
docker-compose restart
查看被ban的记录
docker exec fail2ban fail2ban-client status sshd
如下:
root@:/app/docker/fail2ban# docker exec fail2ban fail2ban-client status sshd
Status for the jail: sshd
|- Filter
| |- Currently failed: 0
| |- Total failed: 0
| `- File list: /var/log/auth.log
`- Actions
|- Currently banned: 3
|- Total banned: 3
`- Banned IP list: 123.58.207.155 92.255.85.107 92.255.85.253
解封IP
docker exec fail2ban fail2ban-client set sshd unbanip 1.1.1.1
ban一个ip
docker exec fail2ban fail2ban-client set sshd banip 103.167.64.9
解封所有
docker exec -it $(docker ps -q --filter name=fail2ban) fail2ban-client unban --all
查看有效的登录用户
grep -E '/bin/bash|/bin/zsh' /etc/passwd
显示当前登录到系统的用户信息
who/w
w 命令显示的是当前系统上已登录的用户会话信息。
具体来说:
- 它会列出 当前在线的所有用户(包括 SSH 登录、TTY、pts 终端等)
- 还会显示每个会话的登录时间、空闲时间、正在运行的命令等信息
- 它不会显示已经退出的历史登录
显示系统中所有的登录和注销记录
last
who 与 last 的区别:
who:显示当前系统中正在登录的用户。
实时信息,反映当前在线的用户。 不包括注销的历史记录。
last:显示所有的登录和注销历史记录。
包括历史记录,反映所有曾经登录过的用户(包括已注销的)。 可以查看每个用户的登录时长和注销信息。
查看历史登录记录
last → 从 /var/log/wtmp 读取历史成功登录记录
lastb → 从 /var/log/btmp 读取失败登录记录(爆破痕迹)
检查是否被爆破成功(成功登录记录)
关键是找 "Accepted password" 或 "Accepted publickey",看是否有陌生 IP。
# 最近成功登录
sudo grep "Accepted" /var/log/auth.log | tail -n 50
更换ssh默认端口
sudo sed -i 's/^#Port .*/Port 50022/; s/^Port .*/Port 50022/' /etc/ssh/sshd_config
ufw allow 50022/tcp comment "ssh"
ufw delete allow ssh
ufw reload
systemctl restart sshd
允许指定的用户SSH
编辑vim /etc/ssh/sshd_config
# 只允许 root 用户登录,其他所有用户都会被拒绝
AllowUsers root
重启sshd
systemctl restart sshd
排查ssh不成功的原因
tail -f /var/log/auth.log
tail -n 40 /var/log/auth.log | grep sshd
docker-compose部署apollo 2.2.0
- 创建文件夹
mkdir -p /app/docker/apollo
- 最终目录结构如下:
tree
.
├── docker-compose.yml
└── sql
├── 01-apolloconfigdb.sql
├── 02-apolloconfigdb.sql
├── 03-init-user.sql
└── 04-init-eureka-url.sql
2 directories, 5 files
- 01-apolloconfigdb.sql 文件内容
services:
apollo-db:
image: mariadb:10.11
container_name: apollo-db
environment:
MYSQL_ROOT_PASSWORD: xoopooth4gie6doo5Aechieteev9genu
MYSQL_USER: apollo
MYSQL_PASSWORD: apollo123
volumes:
- ./sql:/docker-entrypoint-initdb.d
- db_data:/var/lib/mysql
command:
- --default-authentication-plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-uapollo", "-papollo123", "--silent"]
interval: 5s
timeout: 10s
retries: 10
apollo-configservice:
image: apolloconfig/apollo-configservice:2.2.0
container_name: apollo-configservice
depends_on:
apollo-db:
condition: service_healthy
environment:
SPRING_DATASOURCE_DRIVER_CLASS_NAME: com.mysql.cj.jdbc.Driver
SPRING_DATASOURCE_URL: jdbc:mysql://apollo-db:3306/ApolloConfigDB?useSSL=false&characterEncoding=utf8
SPRING_DATASOURCE_USERNAME: apollo
SPRING_DATASOURCE_PASSWORD: apollo123
EUREKA_INSTANCE_HOSTNAME: apollo-configservice
EUREKA_INSTANCE_IP_ADDRESS: apollo-configservice
EUREKA_CLIENT_SERVICE_URL_DEFAULTZONE: http://apollo-configservice:8080/eureka/
EUREKA_SERVER_ENABLE_SELF_PRESERVATION: "false"
EUREKA_SERVER_EVICTION_INTERVAL_TIMER_IN_MS: "5000"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 5
apollo-adminservice:
image: apolloconfig/apollo-adminservice:2.2.0
container_name: apollo-adminservice
depends_on:
apollo-configservice:
condition: service_healthy
environment:
SPRING_DATASOURCE_DRIVER_CLASS_NAME: com.mysql.cj.jdbc.Driver
SPRING_DATASOURCE_URL: jdbc:mysql://apollo-db:3306/ApolloConfigDB?useSSL=false&characterEncoding=utf8
SPRING_DATASOURCE_USERNAME: apollo
SPRING_DATASOURCE_PASSWORD: apollo123
EUREKA_CLIENT_SERVICE_URL_DEFAULTZONE: http://apollo-configservice:8080/eureka/
EUREKA_INSTANCE_HOSTNAME: apollo-adminservice
EUREKA_INSTANCE_IP_ADDRESS: apollo-adminservice
EUREKA_CLIENT_REGISTER_WITH_EUREKA: "true"
EUREKA_CLIENT_FETCH_REGISTRY: "true"
# 显式覆盖所有可能的配置键(不同大小写和格式)
EUREKA_CLIENT_SERVICEURL_DEFAULTZONE: http://apollo-configservice:8080/eureka/
SPRING_CLOUD_CONFIG_ENABLED: "false" # 禁用配置服务器覆盖
SPRING_APPLICATION_JSON: '{"eureka":{"client":{"serviceUrl":{"defaultZone":"http://apollo-configservice:8080/eureka/"}}}}' # 最高优先级
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8090/health"]
interval: 30s
timeout: 10s
retries: 5
apollo-portal:
image: apolloconfig/apollo-portal:2.2.0
container_name: apollo-portal
depends_on:
apollo-configservice:
condition: service_healthy
environment:
SPRING_DATASOURCE_DRIVER_CLASS_NAME: com.mysql.cj.jdbc.Driver
SPRING_DATASOURCE_URL: jdbc:mysql://apollo-db:3306/ApolloPortalDB?useSSL=false&characterEncoding=utf8
SPRING_DATASOURCE_USERNAME: apollo
SPRING_DATASOURCE_PASSWORD: apollo123
APOLLO_PORTAL_ENVS: dev
DEV_META: http://apollo-configservice:8080
PRO_META: http://apollo-configservice:8080
APOLLO_CONFIG_SERVICE: http://apollo-configservice:8080
ports:
- "8070:8070"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8070/health"]
interval: 30s
timeout: 10s
retries: 5
networks:
- nginx_ngu_network #此处是为了加入已经创建好的nginx网络中.用于nginx代理.可选
- default
networks:
nginx_ngu_network:
external: true
volumes:
db_data:
- sql/01-apolloconfigdb.sql
下载文件 https://github.com/apolloconfig/apollo/blob/master/scripts/sql/profiles/mysql-default/apolloconfigdb.sql
- sql/02-apolloconfigdb.sql
下载文件 https://github.com/apolloconfig/apollo/blob/master/scripts/sql/profiles/mysql-default/apolloportaldb.sql
- sql/03-init-user.sql
CREATE USER IF NOT EXISTS 'apollo'@'%' IDENTIFIED BY 'apollo123';
GRANT ALL PRIVILEGES ON ApolloConfigDB.* TO 'apollo'@'%';
GRANT ALL PRIVILEGES ON ApolloPortalDB.* TO 'apollo'@'%';
FLUSH PRIVILEGES
- sql/04-init-eureka-url.sql
非常重要. apollo 2.2.0版本. apollo-adminservice默认的注册中心是http://localhost:8080/eureka/,启动后总是无法找到正常的apollo-configservice.用执行初始化sql的办法修改
UPDATE `ApolloConfigDB`.`ServerConfig`
SET `Value` = 'http://apollo-configservice:8080/eureka/'
WHERE `Key` = 'eureka.service.url';
- 启动
docekr-compose up -d
- 访问 http://localhost:8070
默认登录账户 apollo/admin, 尽快修改密码
docker搭建达梦数据库
Docker 安装
docker run -d -p 30236:5236 \
--restart=always \
--name dm8 \
--privileged=true \
-e PAGE_SIZE=16 \
-e LD_LIBRARY_PATH=/opt/dmdbms/bin \
-e EXTENT_SIZE=32 \
-e BLANK_PAD_MODE=1 \
-e LOG_SIZE=1024 \
-e UNICODE_FLAG=1 \
-e LENGTH_IN_CHAR=1 \
-e INSTANCE_NAME=dm8 \
-e CASE_SENSITIVE=0 \
-e CHARSET=1 \
tommyyusky/dm8_20230808_rev197096_x86_rh6_64
默认账户
SYSDBA/SYSDBA001
达梦官网资料下载
达梦 JDBC 驱动下载
常用命令
修改数据库密码
ALTER USER CURRENT_USER IDENTIFIED BY eizeejee3oh REPLACE SYSDBA001;
# ALTER USER SYSDBA IDENTIFIED BY eizeejee3oh;
环境
root@x:~# cat /etc/issue
Debian GNU/Linux 12 \n \l
Fail2Ban 安装相关
# 安装
apt install fail2ban -y
# 启动进程
systemctl start fail2ban
# 开机启动
systemctl enable fail2ban
查看状态
systemctl status fail2ban.service
发现没有启动成功,控制台如下:
× fail2ban.service - Fail2Ban Service
Loaded: loaded (/lib/systemd/system/fail2ban.service; enabled; preset: enabled)
Active: failed (Result: exit-code) since Mon 2024-08-05 03:41:24 UTC; 3 days ago
Duration: 195ms
Docs: man:fail2ban(1)
Main PID: 1981 (code=exited, status=255/EXCEPTION)
CPU: 160ms
Aug 05 03:41:24 lightsail systemd[1]: Started fail2ban.service - Fail2Ban Service.
Aug 05 03:41:24 lightsail fail2ban-server[1981]: 2024-08-05 03:41:24,878 fail2ban.configreader [1981]: WARNING 'allowipv6' not defined in 'Definition'. Using default one: 'auto'
Aug 05 03:41:24 lightsail fail2ban-server[1981]: 2024-08-05 03:41:24,912 fail2ban [1981]: ERROR Failed during configuration: Have not found any log file for sshd jail
Aug 05 03:41:24 lightsail fail2ban-server[1981]: 2024-08-05 03:41:24,919 fail2ban [1981]: ERROR Async configuration of server failed
Aug 05 03:41:24 lightsail systemd[1]: fail2ban.service: Main process exited, code=exited, status=255/EXCEPTION
解决办法: vim /etc/fail2ban/jail.local
vim /etc/fail2ban/jail.local
#内容如下
[sshd]
enabled = true
port = ssh
logpath = /var/log/auth.log
backend = auto
创建日志文件/var/log/auth.log
touch /var/log/auth.log
重启并且查看状态
systemctl restart fail2ban
systemctl status fail2ban
启动成功,控制台输出如下:
● fail2ban.service - Fail2Ban Service
Loaded: loaded (/lib/systemd/system/fail2ban.service; enabled; preset: enabled)
Active: active (running) since Thu 2024-08-08 09:23:46 UTC; 4s ago
Docs: man:fail2ban(1)
Main PID: 17051 (fail2ban-server)
Tasks: 5 (limit: 2303)
Memory: 14.0M
CPU: 189ms
CGroup: /system.slice/fail2ban.service
└─17051 /usr/bin/python3 /usr/bin/fail2ban-server -xf start
Aug 08 09:23:46 lightsail systemd[1]: Started fail2ban.service - Fail2Ban Service.
Aug 08 09:23:46 lightsail fail2ban-server[17051]: 2024-08-08 09:23:46,319 fail2ban.configreader [17051]: WARNING 'allowipv6' not defined in 'Definition'. Using default one: 'auto'
Aug 08 09:23:46 lightsail fail2ban-server[17051]: Server ready
Linux常用技巧
每次vim的时候总是粘贴不了.需要输入:set mouse-=a回车,才行
解决办法, vim ~/.vimrc 内容如下
set mouse-=a
保存后, souce ~/.vimrc, 再次编辑文件, 就可以粘贴了
apt安装ping
apt install iputils-ping
给泛解析加一个匹配不到的预留映射
vim *.nguone.eu.org.conf
server {
listen 80;
listen 443 ssl;
server_name *.nguone.eu.org;
ssl_certificate /etc/nginx/ssl/vaultwarden.crt;
ssl_certificate_key /etc/nginx/ssl/vaultwarden.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
# 可以选择进行适当的处理或返回404
# 开启HSTS后能够提升到A+. SSL评估 https://myssl.com/
add_header Strict-Transport-Security "max-age=31536000";
return 404;
}
Nginx Docker 部署
创建网络
docker network create --driver=bridge --subnet=172.16.238.0/24 --gateway=172.16.238.1 my_docker_network
version: '3.8'
services:
nginx:
image: nginx:1.21.1
container_name: nginx
ports:
- 80:80
- 443:443
volumes:
- /app/docker/nginx/nginx:/etc/nginx
- /root/.acme.sh/*.nguone.eu.org_ecc/fullchain.cer:/etc/nginx/ssl/vaultwarden.crt:ro
- /root/.acme.sh/*.nguone.eu.org_ecc/*.nguone.eu.org.key:/etc/nginx/ssl/vaultwarden.key:ro
networks:
- my_docker_network
networks:
my_docker_network:
external: true
Nginx https 配置
当前nginx版本
nginx -v
nginx version: nginx/1.21.1
vaultwarden.conf示例配置如下
server {
listen 80; #侦听80端口,如果强制所有的访问都必须是HTTPs的,这行需要注销掉
listen 443 ssl;
server_name vaultwarden.nguone.eu.org;
ssl_certificate /etc/nginx/ssl/vaultwarden.crt;
ssl_certificate_key /etc/nginx/ssl/vaultwarden.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
client_max_body_size 1024m;
# 开启HSTS后能够提升到A+. SSL评估 https://myssl.com/
add_header Strict-Transport-Security "max-age=31536000";
location / {
proxy_set_header HOST $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://vaultwarden;
}
}
添加一个http登录认证 配置如下:
server {
listen 80; #侦听80端口,如果强制所有的访问都必须是HTTPs的,这行需要注销掉
server_name work;
client_max_body_size 1024m;
# 开启HSTS后能够提升到A+. SSL评估 https://myssl.com/
add_header Strict-Transport-Security "max-age=31536000";
location / {
# 启用 HTTP Basic Authentication
auth_basic "Restricted Access"; # 提示信息
auth_basic_user_file /etc/nginx/.htpasswd; # 指定存放用户名和密码的文件
proxy_set_header HOST $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://host.docker.internal:3000;
}
}
生成验证密码,保存在/etc/nginx/.htpasswd
密码错误, 会导致nginx提示500错误
htpasswd -c -b /etc/nginx/.htpasswd nguone AiQuaichei2Eer2C
location
location = /abc {
add_header Content-Type text/plain;
add_header X-Server-IP $server_addr always;
return 200 'Success';
}
解释:
location = /abc:表示精确匹配/abc,只有请求的 URI 正好是/abc时才会匹配这个块.其他以/abc/开头的路径(比如/abc/jlljlk)将不会匹配这个配置,将会返回404- 如果设置为
/abc,那么访问/abc以及/abc开头的任何路径都会当做/abc处理 add_header Content-Type text/plain表示返回的信息是纯文本add_header X-Server-IP $server_addr always强制在响应头信息中返回nginx的IP
匹配进程的名字并且全部杀掉进程
如杀掉所有kafka进程
pgrep -f kafka | xargs kill -9
解释
- pgrep -f kafka:查找所有匹配 kafka 的进程 PID。
- xargs kill -9:将找到的 PID 传递给 kill -9,强制终止所有这些进程。
这个命令将会找到所有 Kafka 相关的进程,并使用 kill -9 发送信号强制终止它们。
注意事项
- 确保匹配准确:确认 pgrep -f kafka 只会匹配到 Kafka 进程,避免误杀其他重要进程。
- 检查进程:在执行命令前,可以运行 pgrep -f kafka 先查看将会被杀掉的进程。
- 这种方式是一条命令的解决方案,但请务必在执行之前确认对系统的影响。
在不关闭shell的情况下重新启动Bash Shell
exec bash
主要作用
- 应用配置更改
- 当你修改了 ~/.bashrc 或其他 shell 配置文件(如 ~/.bash_profile)后,使用 exec bash 可以使这些更改立即生效,而无需重新登录或重启终端
- 刷新环境
- 有时需要重新加载环境变量或 shell 配置时,exec bash 会刷新当前 shell 的所有设置,使得新的环境变量或配置被加载
重置终端root@后的别名.
# 重置PS1
echo "export PS1='[\u@\h \W]\$ '" >> ~/.bashrc && exec bash
端口扫描
安装
sudo apt-get install nmap # Debian/Ubuntu 系统
sudo yum install nmap # CentOS/Red Hat 系统
扫描单个主机
nmap -sT 192.168.1.1
扫描整个网段
nmap -p 1-65535 192.168.1.0/24
查看硬盘类型
cat /sys/block/sda/queue/rotational
#如果输出是 1,则表示该磁盘是 旋转硬盘(HDD)。
#如果输出是 0,则表示该磁盘是 固态硬盘(SSD)。
查看所有自启服务列表
systemctl list-units --type=service
docker 容器安装telnet
# 查看操作系统信息
cat /etc/os-release
# alpine 安装telnet
apk add busybox-extras
grafana 重置admin密码
grafana-cli admin reset-admin-password <new password>
find跳过无权限目录
find / -path /proc -prune -o -name "*.jar" -print
# 等价于
find / -not -path "/proc/*" -name "*.jar" -print
/proc 目录 是一个虚拟文件系统,包含系统和进程的实时信息。
权限限制:某些 /proc 目录下的文件和进程信息只有 root 用户或进程的所有者才能访问,普通用户会遇到 Permission denied 错误。
解决方法:使用 -prune 排除 /proc 目录,避免遍历该目录时出现权限问题。
debian设置上海时区
sudo timedatectl set-timezone Asia/Shanghai
容器内运行arthas防止挂断
# 在openjdk8环境下运行 出现问题的解决方案
# export PATH=$PATH:/usr/lib/jvm/java-1.8-openjdk/bin
pid=1 ;\
touch /proc/${pid}/cwd/.attach_pid${pid} && \
kill -SIGQUIT ${pid} && \
sleep 2 &&
ls /proc/${pid}/root/tmp/.java_pid${pid}
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
windows 多块网卡切换
检查路由表
route print
删除 WLAN(无线网卡)的默认路由
route delete 0.0.0.0 mask 0.0.0.0 172.20.10.1 if 14
删除以太网(Realtek PCIe GbE)的默认路由
route delete 0.0.0.0 mask 0.0.0.0 10.99.95.254
恢复默认路由
route add 0.0.0.0 mask 0.0.0.0 10.99.95.254 if 20 -p
设置上海时区
sudo timedatectl set-timezone Asia/Shanghai
查看磁盘使用情况
df -h /
开启4G的内存缓冲区
sudo fallocate -l 4G /swapfile && \
sudo chmod 600 /swapfile && \
sudo mkswap /swapfile && \
sudo swapon /swapfile && \
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab && \
sudo sysctl vm.swappiness=10 && \
echo 'vm.swappiness=10' | sudo tee -a /etc/sysctl.conf
网络知识积累
局域网(LAN)常用的私有IP地址网段
通常包括以下三个主要的网段,它们是专门保留给私有网络使用的,不会在互联网中路由
-
10.0.0.0/8 网段: 范围:10.0.0.0 - 10.255.255.255 子网掩码:255.0.0.0 可用地址数:16,777,216(即 2^24)
-
172.16.0.0/12 网段: 范围:172.16.0.0 - 172.31.255.255 子网掩码:255.240.0.0 可用地址数:1,048,576(即 2^20)
-
192.168.0.0/16 网段: 范围:192.168.0.0 - 192.168.255.255 子网掩码:255.255.0.0 可用地址数:65,536(即 2^16)
防火墙-firewalld
重载防火墙
firewall-cmd --reload
查看已开启的端口
firewall-cmd --zone=public --list-ports
防火墙-ufw
journalctl查看ssh连接日志
使用 journalctl 查看认证日志
sudo journalctl -u ssh
持续监控这些日志,可以使用 -f 选项,类似于 tail -f
sudo journalctl -u ssh -f
查看所有与认证相关的日志记录
sudo journalctl | grep ssh
查看登录成功的记录
sudo journalctl | grep ssh | grep 'Accepted'
查看被拒绝的记录
sudo journalctl | grep ssh | grep preauth
日志分析
Oct 16 06:10:01 amd2 sshd[7597]: Connection reset by invalid user admin 154.47.27.80 port 42672 [preauth]
对主机名为amd2的VPS进行ssh连接,invalid user 表示无效用户, 即使用不存在的用户admin进行ssh连接. preauth被拒绝 即 用户输入的用户名还未通过认证程序校验,系统已经发现这是一个无效用户并且连接已被重置
删除所有超过 1 秒的日志
sudo journalctl --vacuum-time=1s
清空日志文件(彻底清除)
sudo rm -rf /var/log/journal/*
Linux创建完整用户
创建用户
- 创建用户
sudo useradd -m -s /bin/bash myuser
- 设置用户密码
sudo passwd myuser
给用户赋予sudo权限
- 添加用户到 sudo 组
# CentOS
sudo usermod -aG wheel myuser
# Debian
sudo usermod -aG sudo myuser
wheel组的用 配置无密码 sudo 权限
注意这是放行所有wheel组的用户, 无密码执行sudo
sudo visudo
找到这一行 %wheel ALL=(ALL) NOPASSWD: ALL
将前面的#去掉.
指定用户,配置无密码执行sudo权限
新增一行
# 指定用户不需要输入密码,执行sudo, 比如sudo -i 或者 sudo su - root
myuser ALL=(ALL) NOPASSWD:ALL
# 指定用户不需要输入密码,仅限于执行/bin/chmod
# myuser ALL=(ALL) NOPASSWD: /bin/chmod
ssh-keygen 生成最新的密钥对
ssh-keygen 生成最新的密钥对,通常建议使用 Ed25519 算法,因为它安全、速度快且体积小,是当前推荐的现代密钥类型
ssh-keygen -t ed25519 -C "your_email@example.com"
其他辅助性命令
- 查看所有用户
cat /etc/passwd
- 查看用户组
cat /etc/group
- 查看用户的权限和组
id myuser
会输出类似于以下的信息
uid=1001(myuser) gid=1001(myuser) groups=1001(myuser),10(wheel)
- 查看所有组
getent passwd
- 使用 groups 命令查看当前用户的组
groups
- 使用 getent 命令检查特定组
getent group docker
- 将用户添加到 docker 组
sudo usermod -aG docker myuser
添加后, 执行sudo docker 命令可能提示无权限. 解决办法有两种:
- 完全退出并重新登录
- newgrp docker
删除一个用户
sudo userdel -r xxxx
禁用root执行ssh
谨慎操作,操作前至少要保证有1个非root用户可以正常ssh登录
vim /etc/ssh/sshd_config
末尾追加
# 只允许 myuser 用户登录,其他所有用户都会被拒绝
AllowUsers myuser
重启sshd
sudo systemctl restart sshd
此时再用root登录就会看到
2025-08-09T07:32:11.673498+08:00 xxxx sshd[1390595]: User root from 111.119.221.153 not allowed because not listed in AllowUsers
Linux历史记录
使用 HISTSIZE 和 HISTFILESIZE 将这两个环境变量设置为 0,这样将不会记录任何历史记录
以在你的 shell 配置文件(如 ~/.bashrc 或 ~/.bash_profile)中添加以下行
export HISTSIZE=0
export HISTFILESIZE=0
刷新终端
source ~/.bashrc
临时禁用历史记录
set +o history
临时启用历史记录
set -o history
删除历史文件
rm ~/.bash_history
Linux代理搭建和使用
sudo yum install squid
sudo systemctl start squid
sudo systemctl enable squid
- 查看配置文件
cat /etc/squid/squid.conf
默认配置如下
http_port 8087
cache_mem 128 MB
cache_dir ufs /var/spool/squid 4096 16 256
cache_effective_user squid #设置用户
cache_effective_group squid #设置用户组
access_log /var/log/squid/access.log #设置访问日志文件
cache_log /var/log/squid/cache.log #设置缓存日志文件
cache_store_log /var/log/squid/store.log #设置缓存记录文件
visible_hostname cdn.abc.com #设置squid服务器主机名
cache_mgr root@root.com
acl all src 0.0.0.0/0.0.0.0 #设置访问控制列表,默认开启
http_access allow all
acl client dstdomain -i www.abc.com #找到TAG: acl标签,在其最后添加下面内容
http_access deny client #禁止所有客户机访问www.abc.com域名
acl client131 src 192.168.237.131 #禁止IP地址为192.168.237.131的客户机访问外网
http_access deny client131
acl client129 dst 192.168.237.129 #禁止所有用户访问IP地址为192.168.237.129的网站
http_access deny client129
acl client163 url_regex -i 163.com #禁止所有用户访问域名中包含有163.com的网站
http_access deny client163
acl clientdate src 192.168.237.0/255.255.255.0 #禁止这个网段所有的客户机在周一到周五的18:00-21:00上网
acl worktime time MTWHF 18:00-21:00
http_access deny clientdate worktime
#acl clientxiazai urlpath_regex -i \.mp3$ \.exe$ \.zip$ \.rar$
#http_access deny clientxiazai #禁止客户机下载*.mp3、*.exe、*.zip和*.rar类型的文件
- 在需要代理的机器上执行
export http_proxy=http://instance1_ip:8087
export https_proxy=http://instance1_ip:8087
docker使用代理
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo nano /etc/systemd/system/docker.service.d/http-proxy.conf
http-proxy.conf内容如下:
[Service]
Environment="HTTP_PROXY=http://instance1_ip:8087"
Environment="HTTPS_PROXY=http://instance1_ip:8087"
Environment="NO_PROXY=localhost,127.0.0.1"
重载系统守护进程并重启 Docker 服务
sudo systemctl daemon-reload
sudo systemctl restart docker
自签证书
特别注意openssl版本
低版本按以下命令生成的自签证书,有可能添加信任后浏览器仍然提示无法信息.当前环境版本
OpenSSL 3.0.15
root@tw:~/ssl# openssl version
OpenSSL 3.0.15 3 Sep 2024 (Library: OpenSSL 3.0.15 3 Sep 2024)
低版本的openssl升级
apt update
apt install openssl -y
生成带有 Subject Alternative Name (SAN) 的自签名证书。现代浏览器(如 Chrome 和 Firefox)要求证书中必须明确设置 SAN,否则即使 CN 匹配也会拒绝连接。 使用
openssl x509 -in work.xyz.me.crt -text -noout确认证书中是否有 SAN 字段
单域名
openssl req -x509 -nodes -days 36500 -newkey rsa:2048 \
-keyout work.xyz.me.key -out work.xyz.me.crt \
-out work.xyz.me.csr \
-subj "/C=CN/ST=Shanghai/L=Shanghai/O=My Company/OU=IT Department/CN=work.xyz.me" \
-addext "subjectAltName=DNS:work.xyz.me"
泛解析域名
openssl req -x509 -nodes -days 36500 -newkey rsa:2048 \
-keyout work.xyz.me.key -out work.xyz.me.crt \
-subj "/C=CN/ST=Shanghai/L=Shanghai/O=My Company/OU=IT Department/CN=*.xyz.me" \
-addext "subjectAltName=DNS:*.xyz.me"
软路由安装
修改静态IP
特别注意,要添加网关,否则无法上网,ping外网不通 特别注意,要添加dns,否则无法解析域名 网关指向主路由IP 192.168.1.1(每个路由器可能不同,可以手机连接WIFI,网络详细中查看)
vi /etc/config/network,找到 config interface 'lan' 部分,按以下格式调整成自己的信息
config interface 'lan'
option type 'bridge'
option ifname 'eth0'
option proto 'static'
option ipaddr '192.168.1.100'
option netmask '255.255.255.0'
option gateway '192.168.1.1'
option ip6assign '60'
option dns '192.168.1.1'
option dns '8.8.8.8'
修改好之后, 重启网络 service network restart
然后查看路由,没看到网关192.128.1.1,表示网关没有添加
root@OpenWrt:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 br-lan
root@OpenWrt:~# ip route
192.168.1.0/24 dev br-lan proto kernel scope link src 192.168.1.100
临时添加网关测试,如果能上网,通过修改/etc/config/network配置持久化即可
root@OpenWrt:~# ip route add default via 192.168.1.1
root@OpenWrt:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 br-lan
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 br-lan
root@OpenWrt:~# ip route
default via 192.168.1.1 dev br-lan proto static
192.168.1.0/24 dev br-lan proto kernel scope link src 192.168.1.100
root@OpenWrt:~# ping baidu.com
PING baidu.com (39.156.66.10): 56 data bytes
64 bytes from 39.156.66.10: seq=0 ttl=53 time=29.502 ms
64 bytes from 39.156.66.10: seq=1 ttl=53 time=29.328 ms
64 bytes from 39.156.66.10: seq=2 ttl=53 time=29.238 ms
opkg update报错解决
rm -rf /etc/opkg/*
/etc/opkg.conf内容如下:
src/gz openwrt_base https://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/18.06.9/packages/x86_64/base
src/gz openwrt_luci https://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/18.06.9/packages/x86_64/luci
src/gz openwrt_packages https://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/18.06.9/packages/x86_64/packages
src/gz openwrt_routing https://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/18.06.9/packages/x86_64/routing
samba模板配置备份
[global]
netbios name = |NAME|
interfaces = |INTERFACES|
server string = |DESCRIPTION|
unix charset = |CHARSET|
workgroup = |WORKGROUP|
## This global parameter allows the Samba admin to limit what interfaces on a machine will serve SMB requests.
bind interfaces only = yes
## time for inactive connections to-be closed in minutes
deadtime = 15
## disable core dumps
enable core files = no
## set security (auto, user, domain, ads)
security = user
## This parameter controls whether a remote client is allowed or required to use SMB encryption.
## It has different effects depending on whether the connection uses SMB1 or SMB2 and newer:
## If the connection uses SMB1, then this option controls the use of a Samba-specific extension to the SMB protocol introduced in Samba 3.2 that makes use of the Unix extensions.
## If the connection uses SMB2 or newer, then this option controls the use of the SMB-level encryption that is supported in SMB version 3.0 and above and available in Windows 8 and newer.
## (default/auto,desired,required,off)
#smb encrypt = default
## set invalid users
invalid users = root
## map unknow users to guest
map to guest = Bad User
## allow client access to accounts that have null passwords.
null passwords = yes
## The old plaintext passdb backend. Some Samba features will not work if this passdb backend is used. (NOTE: enabled for size reasons)
## (tdbsam,smbpasswd,ldapsam)
passdb backend = smbpasswd
## Set location of smbpasswd ('smbd -b' will show default compiled location)
#smb passwd file = /etc/samba/smbpasswd
## LAN (IPTOS_LOWDELAY TCP_NODELAY) WAN (IPTOS_THROUGHPUT) WiFi (SO_KEEPALIVE) try&error for buffer sizes (SO_RCVBUF=65536 SO_SNDBUF=65536)
socket options = IPTOS_LOWDELAY TCP_NODELAY
## If this integer parameter is set to a non-zero value, Samba will read from files asynchronously when the request size is bigger than this value.
## Note that it happens only for non-chained and non-chaining reads and when not using write cache.
## The only reasonable values for this parameter are 0 (no async I/O) and 1 (always do async I/O).
## (1/0)
#aio read size = 0
#aio write size = 0
## If Samba has been built with asynchronous I/O support, Samba will not wait until write requests are finished before returning the result to the client for files listed in this parameter.
## Instead, Samba will immediately return that the write request has been finished successfully, no matter if the operation will succeed or not.
## This might speed up clients without aio support, but is really dangerous, because data could be lost and files could be damaged.
#aio write behind = /*.tmp/
## lower CPU useage if supported and aio is disabled (aio read size = 0 ; aio write size = 0)
## is this still broken? issue is from 2019 (NOTE: see https://bugzilla.samba.org/show_bug.cgi?id=14095 )
## (no, yes)
#use sendfile = yes
## samba will behave as previous versions of Samba would and will fail the lock request immediately if the lock range cannot be obtained.
#blocking locks = No
## disable loading of all printcap printers by default (iprint, cups, lpstat)
load printers = No
printcap name = /dev/null
## Enabling this parameter will disable Samba's support for the SPOOLSS set of MS-RPC's.
disable spoolss = yes
## This parameters controls how printer status information is interpreted on your system.
## (BSD, AIX, LPRNG, PLP, SYSV, HPUX, QNX, SOFTQ)
printing = bsd
## Disable that nmbd is acting as a WINS server for unknow netbios names
#dns proxy = No
## win/unix user mapping backend
#idmap config * : backend = tdb
## Allows the server name that is advertised through MDNS to be set to the hostname rather than the Samba NETBIOS name.
## This allows an administrator to make Samba registered MDNS records match the case of the hostname rather than being in all capitals.
## (netbios, mdns)
mdns name = mdns
## Clients that only support netbios won't be able to see your samba server when netbios support is disabled.
#disable netbios = Yes
## Setting this value to no will cause nmbd never to become a local master browser.
#local master = no
## (auto, yes) If this is set to yes, on startup, nmbd will force an election, and it will have a slight advantage in winning the election. It is recommended that this parameter is used in conjunction with domain master = yes, so that nmbd can guarantee becoming a domain master.
#preferred master = yes
## (445 139) Specifies which ports the server should listen on for SMB traffic.
## 139 is netbios/nmbd
#smb ports = 445 139
## This is a list of files and directories that are neither visible nor accessible.
## Each entry in the list must be separated by a '/', which allows spaces to be included in the entry. '*' and '?' can be used to specify multiple files or directories as in DOS wildcards.
veto files = /Thumbs.db/.DS_Store/._.DS_Store/.apdisk/
## If a directory that is to be deleted contains nothing but veto files this deletion will fail unless you also set the delete veto files parameter to yes.
delete veto files = yes
################ Filesystem and creation rules ################
## reported filesystem type (NTFS,Samba,FAT)
#fstype = FAT
## Allows a user who has write access to the file (by whatever means, including an ACL permission) to modify the permissions (including ACL) on it.
#dos filemode = Yes
## file/dir creating rules
#create mask = 0666
#directory mask = 0777
#force group = root
#force user = root
#inherit owner = windows and unix
################################################################
kubernetes
Kubernetes 是一个开源的容器编排引擎,用来对容器化应用进行自动化部署、扩缩和管理
搭建一个kubernetes集群
安装工具kubectl
安装
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 查看版本
kubectl version --client
安装 bash-completion
apt-get install bash-completion -y && source /usr/share/bash-completion/bash_completion
全局启用启动 kubectl 自动补全功能
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
sudo chmod a+r /etc/bash_completion.d/kubectl
source ~/.bashrc
安装集群:生产环境
安装netcat-openbsd
apt update && apt install netcat-openbsd -y
# 用于直观地看端口是否启用
root@tw:~# nc 127.0.0.1 443 -v
Connection to 127.0.0.1 443 port [tcp/https] succeeded!
安装 kubeadm
sudo apt-get update
# apt-transport-https 可能是一个虚拟包(dummy package);如果是的话,你可以跳过安装这个包
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
ip route show | grep "default via"
default via 10.140.0.1 dev ens4 proto dhcp src 10.140.0.7 metric 100
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
cat /etc/kubernetes/kubelet.conf | grep server
重置k8s集群
sudo kubeadm reset
rm -rf /etc/cni/net.d
rm -rf $HOME/.kube/config
rm -rf /etc/kubernetes
docker run -d --name=rancher --privileged --network nginx_ngu_network --memory="2g" rancher/rancher:latest
dd if=/dev/zero of=/swapfile bs=1M count=2048
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
docker logs --tail 10 nginx
列出所有命名空间下的所有的服务
可以看到端口
kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cattle-fleet-local-system fleet-agent ClusterIP None <none> <none> 30m
cattle-provisioning-capi-system capi-webhook-service ClusterIP 10.101.178.158 <none> 443/TCP 29m
cert-manager cert-manager ClusterIP 10.103.216.116 <none> 9402/TCP 35m
cert-manager cert-manager-webhook ClusterIP 10.102.68.102 <none> 443/TCP 35m
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3h46m
default nginx-service NodePort 10.104.63.107 <none> 80:30001/TCP 79m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 3h46m
删除服务
kubectl delete svc nginx-service -n default
kubectl delete deployment nginx -n default
root@tw:/app/docker/nginx/nginx/conf.d# kubectl get deployments -n default
No resources found in default namespace.
删除 Namespace
kubectl get namespace cattle-system -o json
kubectl patch namespace cattle-system -p '{"metadata":{"finalizers":null}}'
kubectl get namespaces
kubectl delete all --all -n cattle-system
kubectl get all -n cattle-system
kubectl delete namespace cattle-system --force --grace-period=0
kubectl get namespace cattle-system -o json > cattle-system.json
kubectl delete validatingwebhookconfiguration rancher.cattle.io
kubectl delete validatingwebhookconfiguration cert-manager-webhook
方法一:将服务类型修改为 LoadBalancer
如果您使用的是云环境(如 GCP、AWS、Azure),可以通过将服务类型改为 LoadBalancer 来使 Rancher 获得一个外部 IP 地址。
执行以下命令来修改 Rancher 服务类型:
bash
复制代码
kubectl -n cattle-system patch svc rancher -p '{"spec":{"type":"LoadBalancer"}}'
此时,您可以通过 EXTERNAL-IP 来访问 Rancher。例如:
bash
复制代码
kubectl -n cattle-system get svc rancher
您将看到 EXTERNAL-IP 字段已分配一个外部 IP 地址,您可以使用该 IP 地址在浏览器中访问 Rancher UI。
方法二:将服务类型修改为 NodePort
如果您没有负载均衡器或不希望使用它,您可以将服务类型修改为 NodePort,然后使用集群节点的外部 IP 和端口访问 Rancher。
执行以下命令来修改 Rancher 服务类型:
bash
复制代码
kubectl -n cattle-system patch svc rancher -p '{"spec":{"type":"NodePort"}}'
然后,使用以下命令查看端口映射:
bash
复制代码
kubectl -n cattle-system get svc rancher
您将看到类似如下的输出:
scss复制代码NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rancher NodePort 10.104.162.113 <none> 80:30001/TCP 1m
如果 Rancher 部署了多个 Pod,可以通过以下命令查看所有 Pod 的日志:
bash
复制代码
kubectl logs -n cattle-system -l app=rancher --follow
helm安装的rancher重置admin密码
cp /root/.kube/config .
KUBECONFIG=./config
kubectl --kubeconfig $KUBECONFIG -n cattle-system exec $(kubectl --kubeconfig $KUBECONFIG -n cattle-system get pods -l app=rancher --no-headers | head -1 | awk '{ print $1 }') -c rancher -- reset-password
kubectl get svc --namespace default等价于 kubectl get svc --namespace default
kubectl get svc --all-namespaces表示列出所有空间下的服务
# dokcer方式搭建
docker run -d --privileged -p 60080:80 -p 60443:443 -v ./rancher_data:/var/lib/rancher --restart=always --name rancher-2.7.1 rancher/rancher:v2.7.1
helm方式搭建
helm install rancher rancher-latest/rancher \
--namespace cattle-system \
--set hostname=k8s.nguone.eu.org --set bootstrapPassword=Ni4phughiotieCoo
kubectl apply -f nginx-pvc.yaml
kubectl get pvc
kubectl apply -f nginx-deployment.yaml
kubectl apply -f nginx-service.yaml
kubectl delete pvc nginx-pvc
kubectl apply -f nginx-test-pod.yaml
让其他节点加入到
个体词

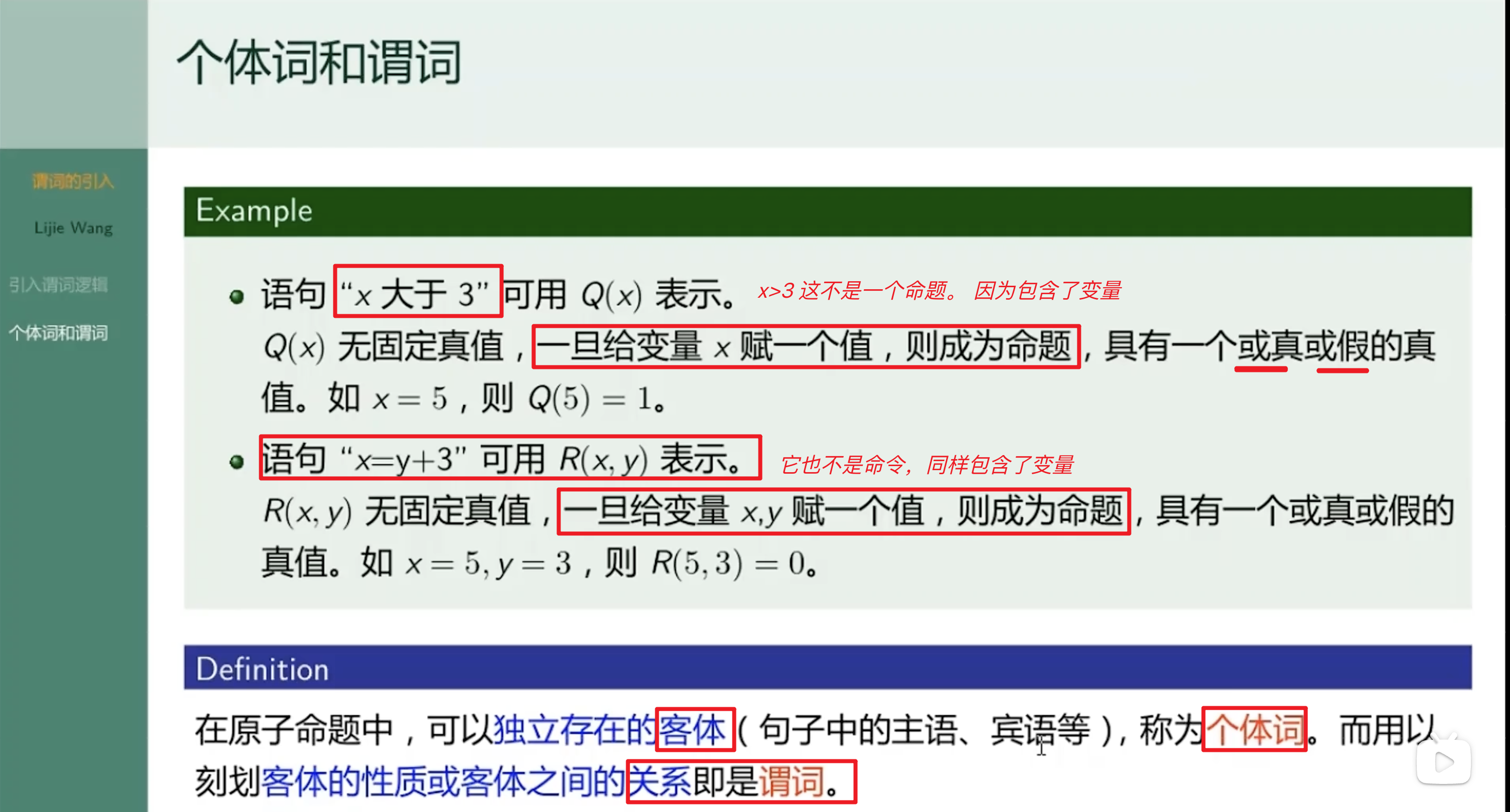
谓词

复合命题的谓词符号化

总结

量词




符号函数
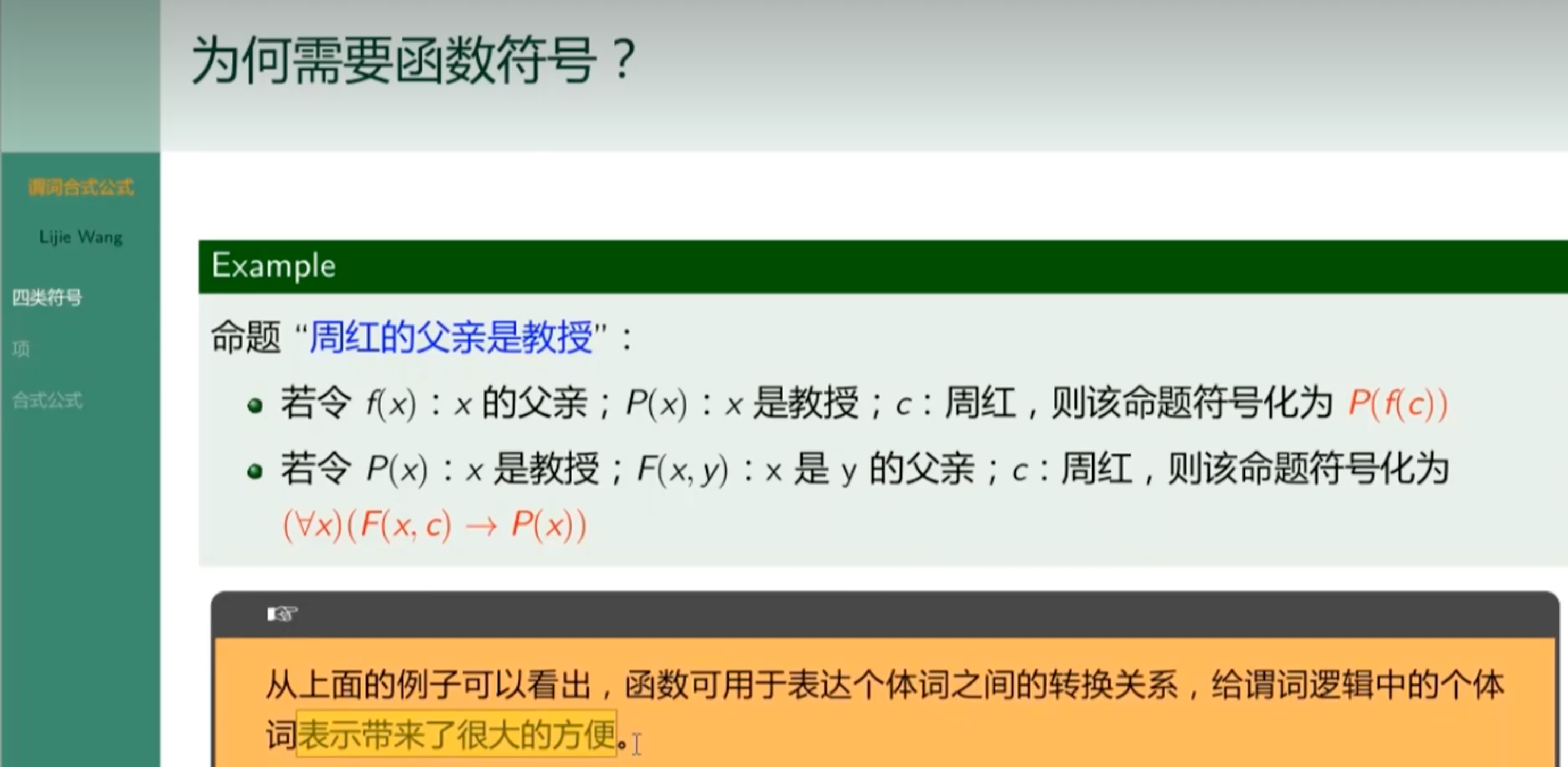

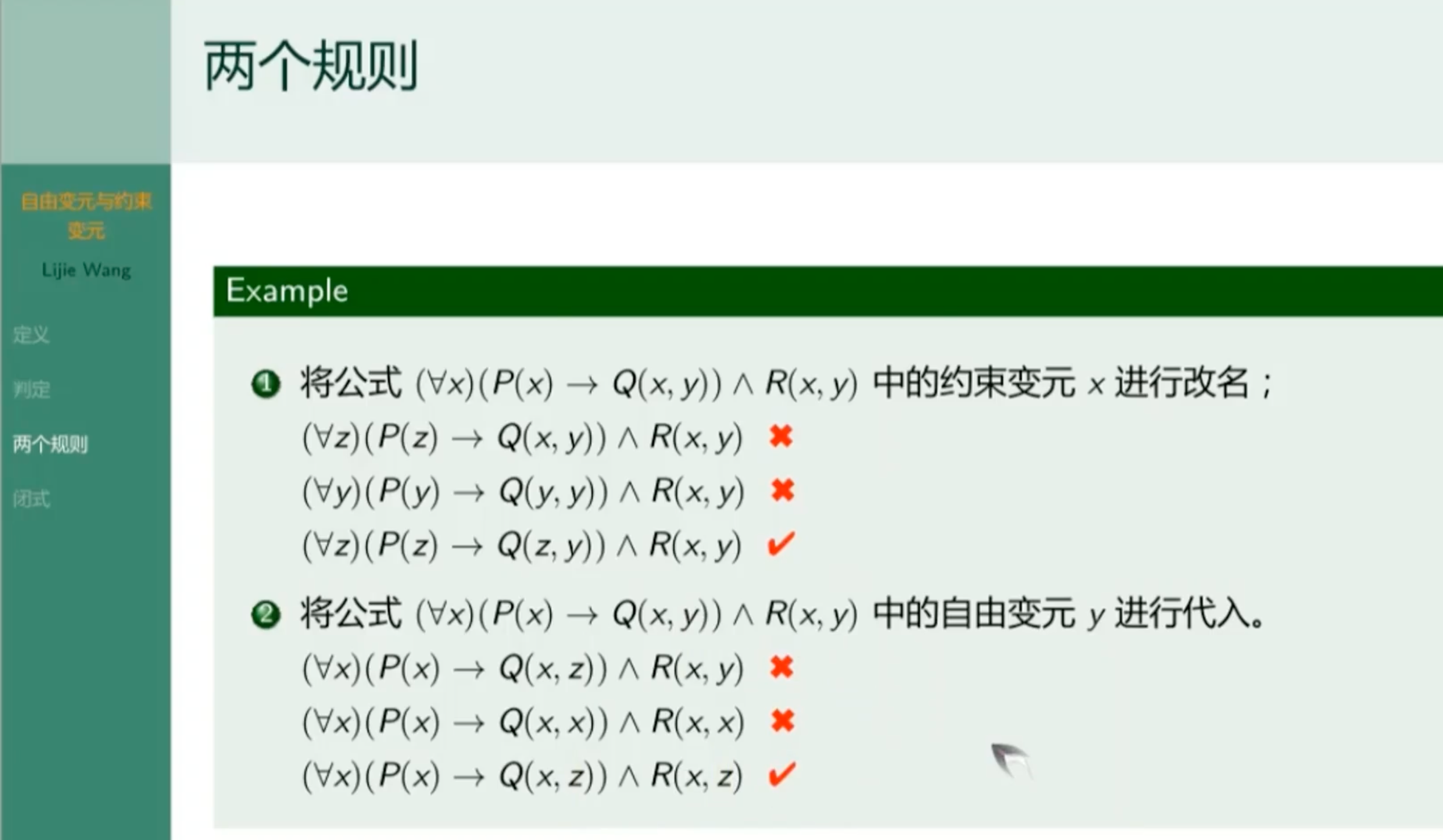
自由变元和约束变元

举例

两个规则

闭式

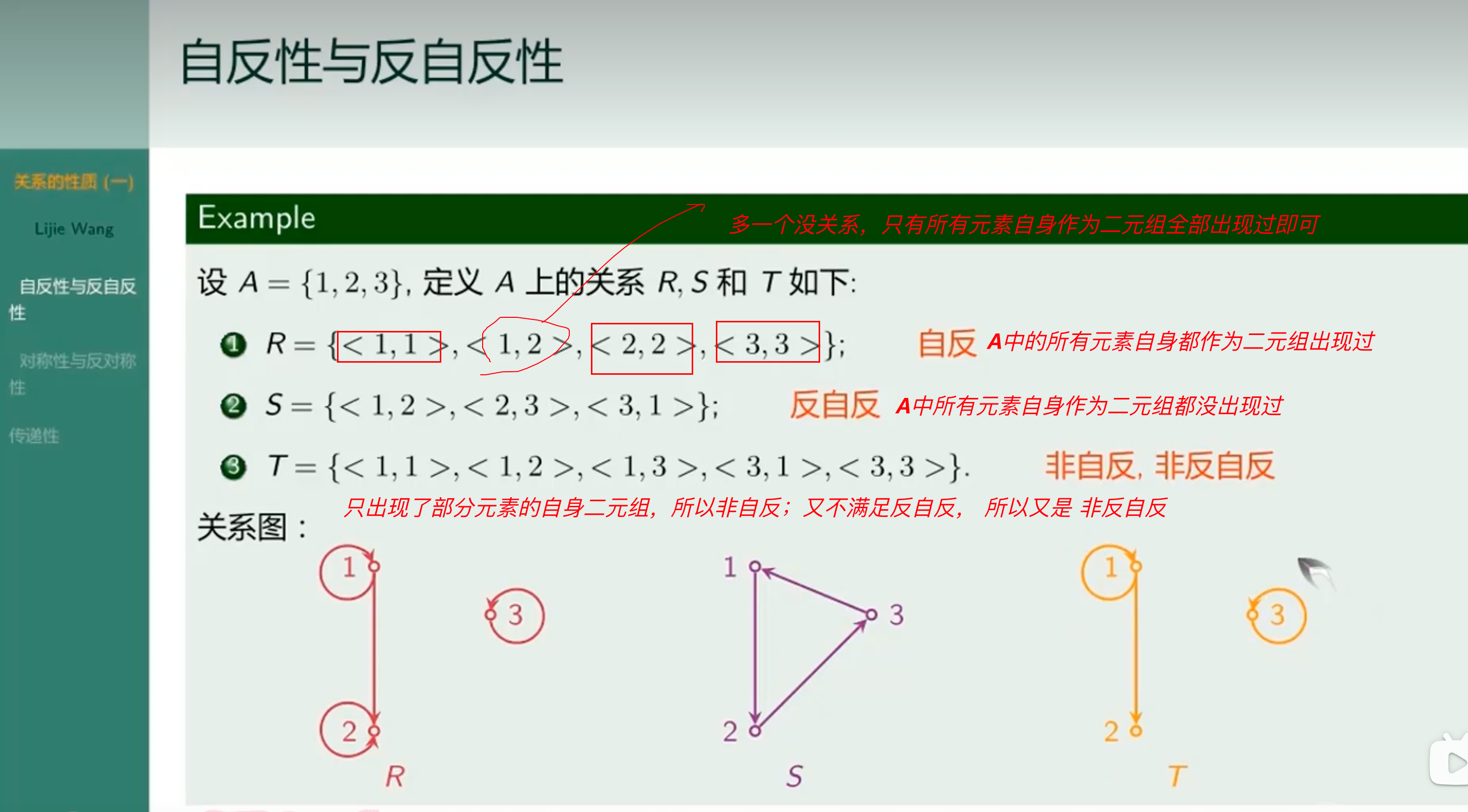
自反性与反自反性

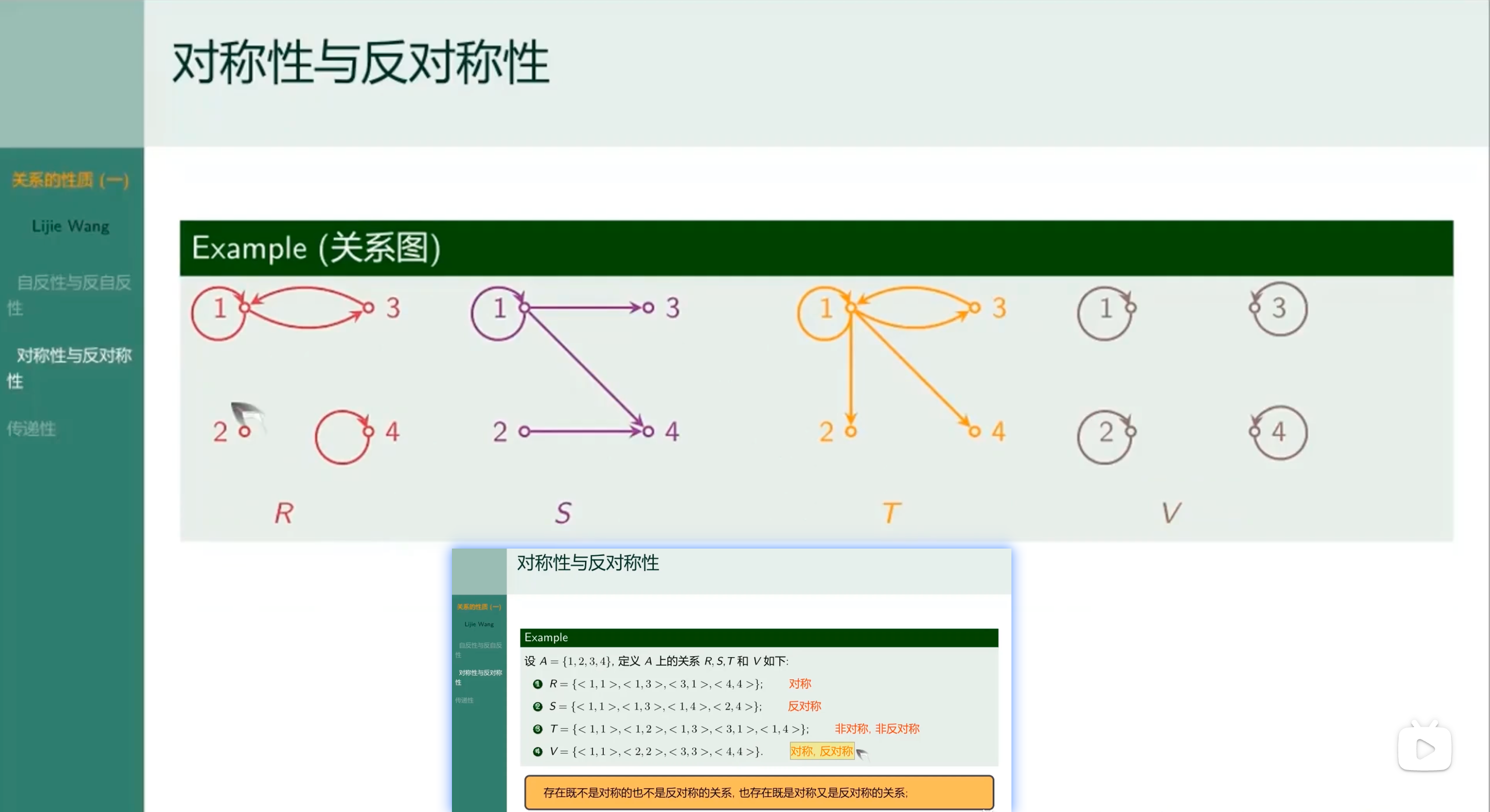
对称性与反对称性
传递性

关系性质的保守性

闭包求解
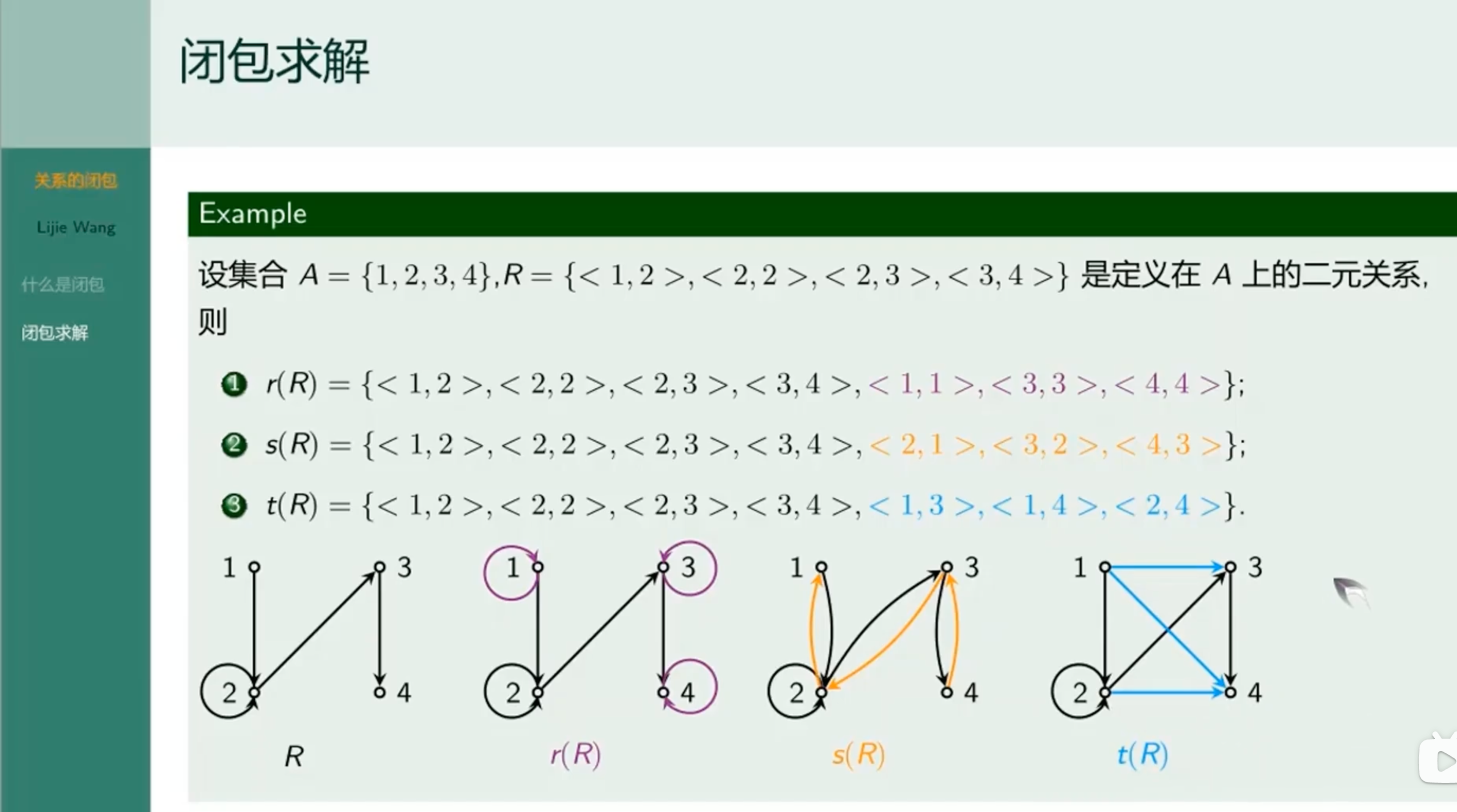
利用关系运算求闭包

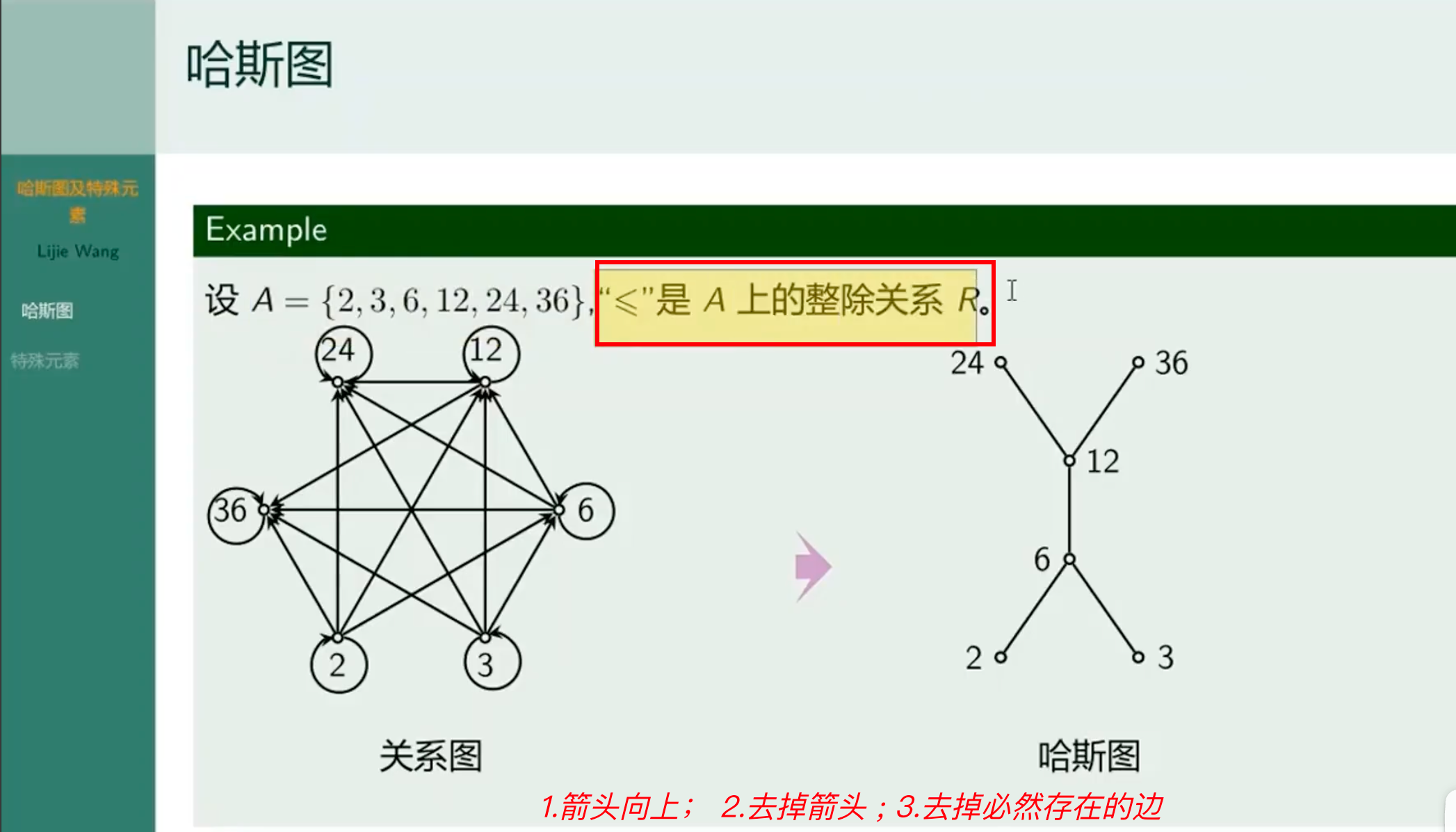
哈斯图
最大元和最小元

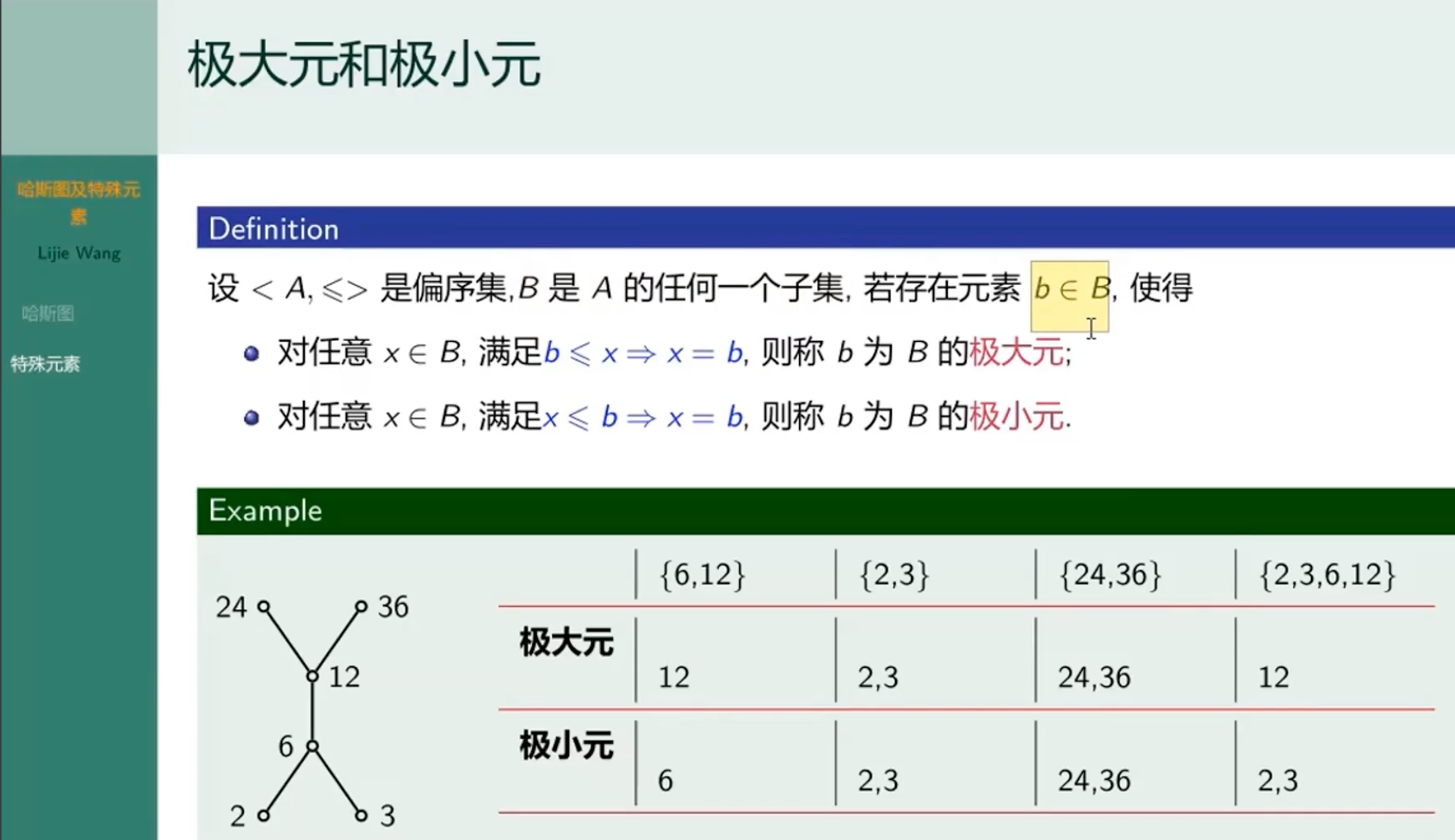
极大元和极小元
总结

上下(确)界关系总结

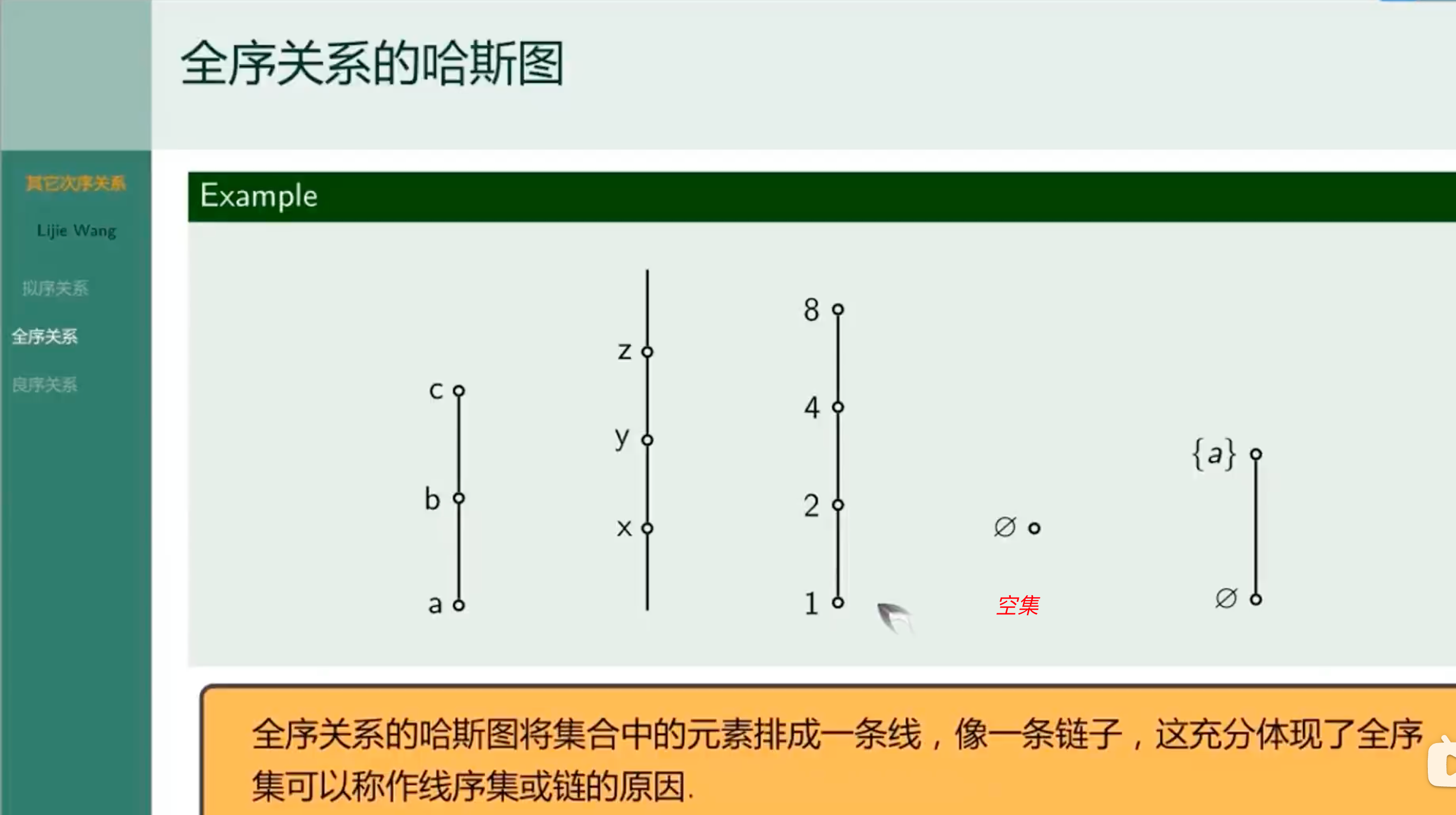
全序关系的哈斯图
良序关系

函数

函数的数量

关系和函数的差别

函数类型

函数的复合


保守性

结点的度数

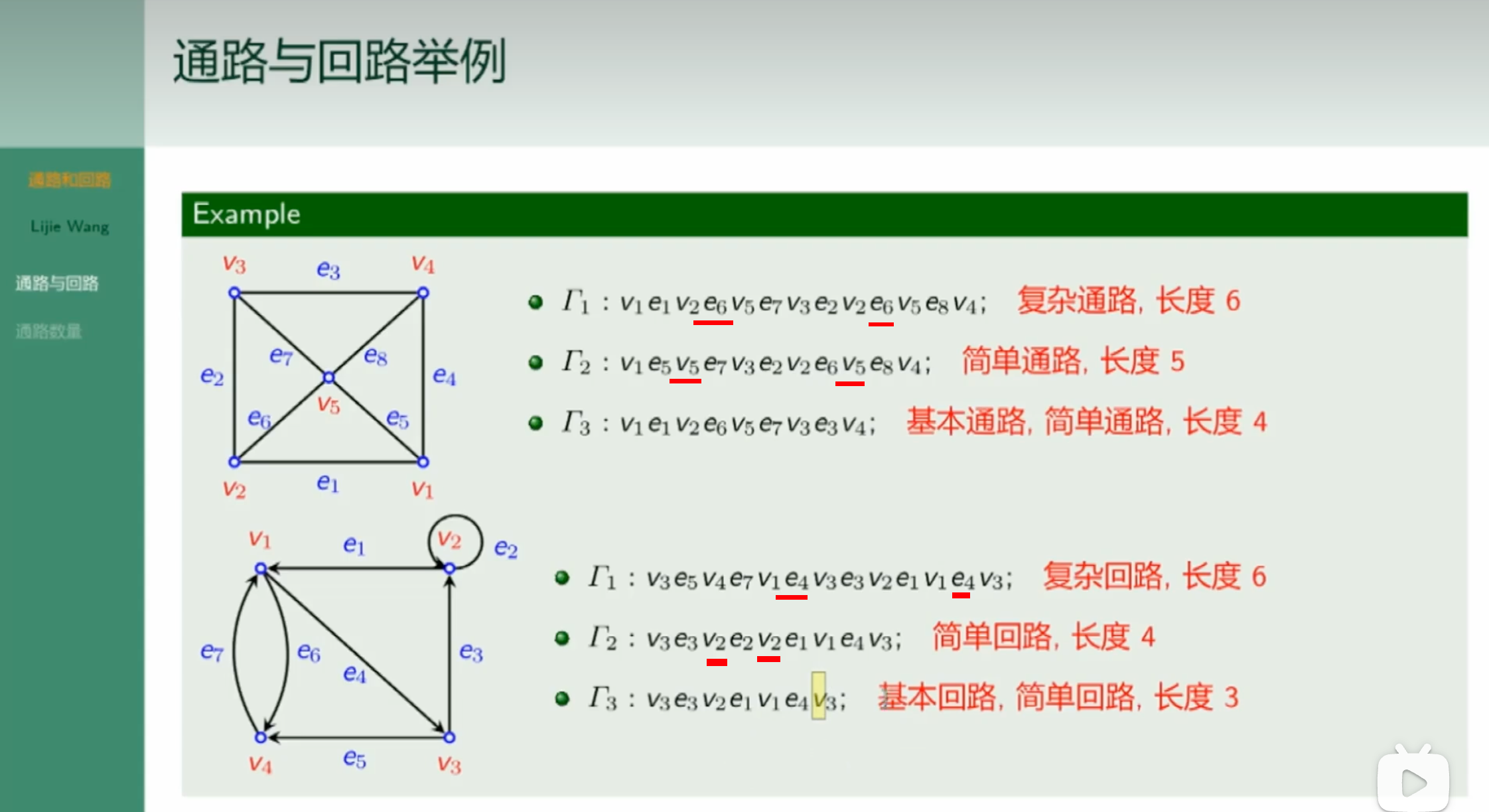
通路与回路举例
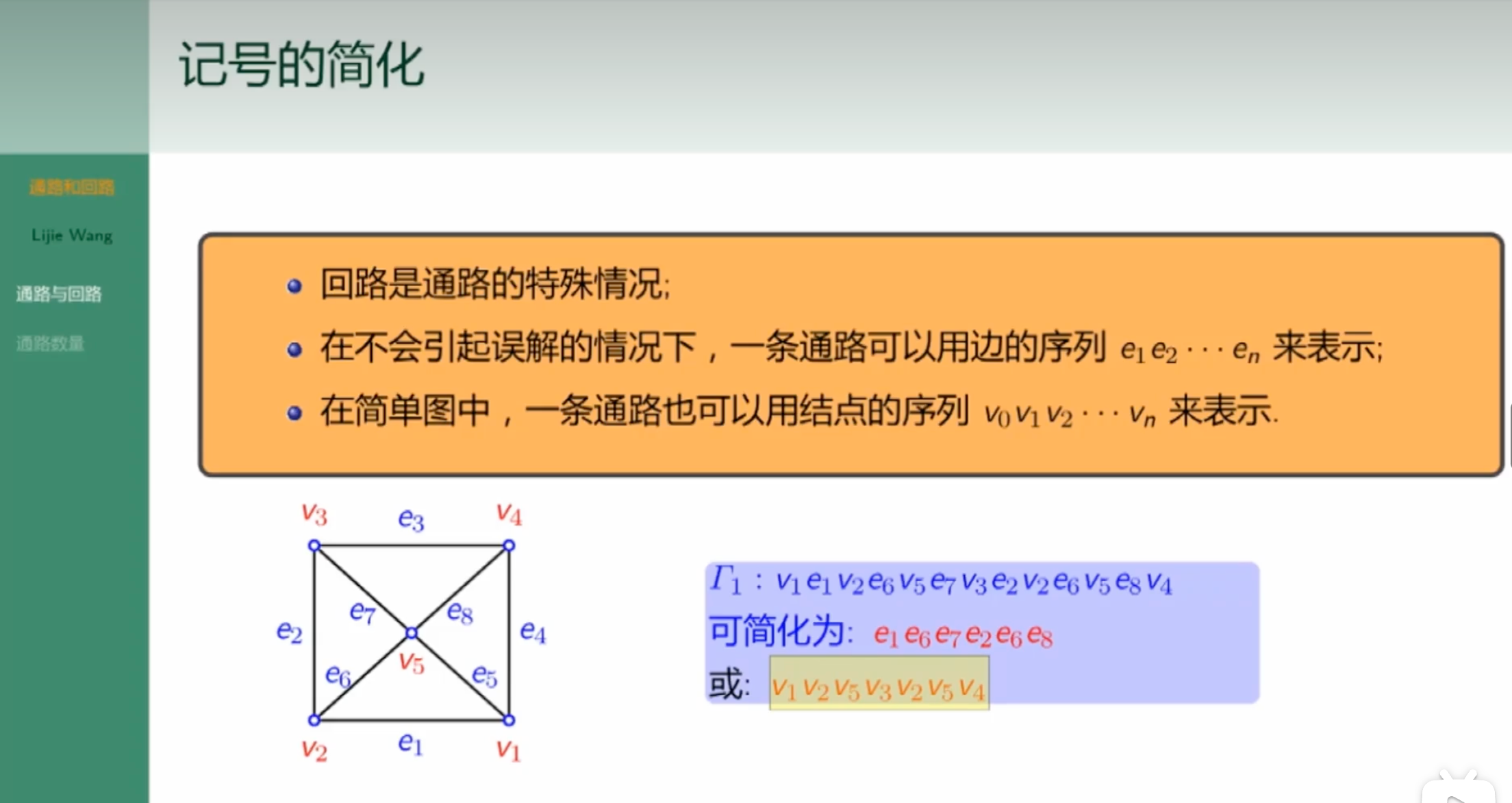
记号的简化
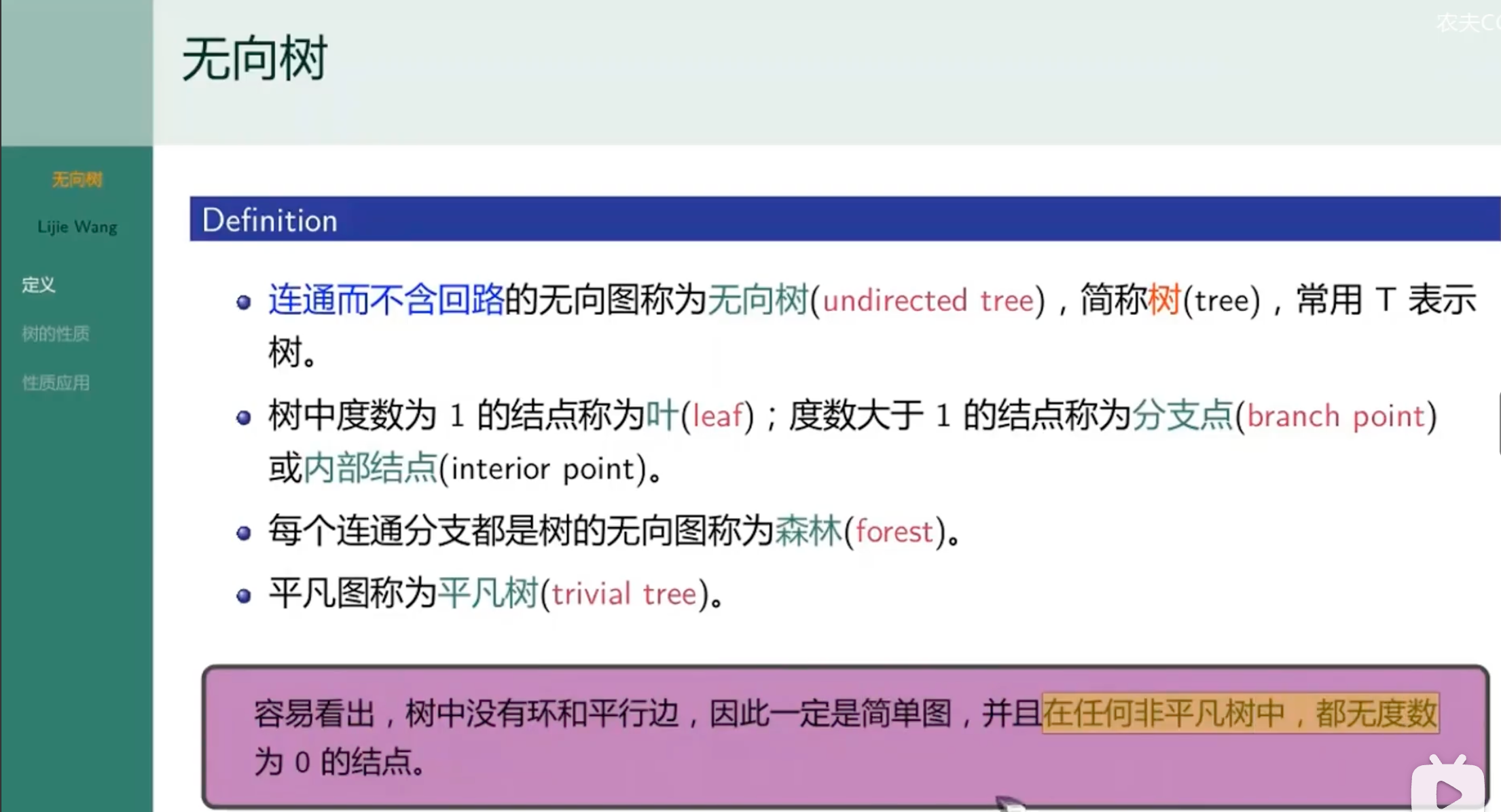
树
无向树
Python基础
基础语法
多行语句
反斜杠\用来连接多行代码
>>>str = "Hello" + \
" World"
>>>print(str)
Hello World
注释
-
单行注释, 用#表示
#这是一个单行注释
-
多行注释,用3个单引号或者双引号表示
-
```3个单引号 表示的多行注释 ``` -
"""3个双引号 表示的多行注释 """
-
同一行显示多条语句
>>> x=123;y=z=1
>>> x
123
>>> y
1
多个语句构成代码组
if True: #结尾的冒号不能省略
print('true')
elif 2>1: # 特别注意,是elif,不是elseif
print('2>1')
else :
print('else')
五个标准的数据类型
String(字符串)
str1 = "abc" #,str2 定义多个字符串的时候,第一个字符串后直接跟逗号定义另一个字符串,在Python 3.11.2中,会报错.这里的#表示注释
str1 = str2 = 'abc'
str1 = """3a""";str2 = """3b"""
str = '''3a'''
[头下标:尾下标]
特别注意,包头不包尾
>>> str="""12345"""
>>> str[1:2]
'2'
>>> str[2:4]
'34'
Numbers(数字)
var1=var2=100
List(列表)
>>> list=['a','b','c','d']
>>> list[0] # 输出列表的第一个元素
'a'
>>> list[1:3] # 输出第二个至第三个元素
['b', 'c']
>>> list*2 #输出列表两次
['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd']
>>> arr=[1,2,3]
>>> list+arr # 两个列表拼接在一起行成1个新的列表
['a', 'b', 'c', 'd', 1, 2, 3]
>>> list[2:] #输出从第3个元素开始的所有元素
['c', 'd']
Tuple(元组)
元组类似于列表,但是,元组不能二次赋值,相当于只读表
Dictionary(字典)
常用函数
北派经方学术
我个人是恨死了一位人称:天医星的叶天士, 由于此人是清朝明医, 再加上后来的吴鞠通加了一点油就出现温病派, 写了温病条辨一书, 也因此二人从此误导了中国人研习中医的领域
汉唐中医节选
内容来源于汉唐中医, 以及我的读后感总结行成
AIDS
总结: AIDS症状为阳明热症, 按照中医里论, 阳明无死症
如何保养自己
倪师经典比喻: 如同吃完饭要清洗碗快一样重要, 每天固定勤擦拭, 必然不生病
- 每天早上起床时, 足尚未踏地, 就先服用昨晚睡前准备好的六味地黄丸30粒, 并且使用事先备好的凉开水里面加一点盐
- 六味地黄丸号是相传两千年的丸剂, 但是一般世面上卖的都是用六味药等量来制作, 这是不正确的
- 每天晚睡前服用一些疏肝解毒的中药
- 我们接触的环境已经受到极高的污染
- 食物的种类太多, 很难去分辨其是否有受到污染
- 外面餐厅用膳, 也不知道他们加入多少味精或食物已经储存多久
- 中医认为大肠与肺为表里, 是故大肠有燥矢屯积, 则浊气必然反逆入肺
- 不但造成口臭
- 更且使皮肤变坏且粗造
- 长期服用六味地黄丸或是一些疏肝解毒中药的人是不会便秘的
- 请买些猪肥肉回来, 自己榨取些猪油来做饭菜
- 饥饿与过饱
- 就是时常保持一点点饿的状态远比时常胃肠胀满的状况要健康好多, 而且也不容易变老, 又长寿, 又不生病, 所以如果是上班足应该一天两餐就够了
总结:
- 每天早上吃六味地黄丸, 水中加入少量盐(青盐或者海盐, 盐味咸, 咸味入肾)这是为了养肾;丸药,药缓力专
- 每天晚上吃点疏肝解毒的药品, 帮助肝脏解毒; 现代人生活压力大, 疏肝解郁可以让身体舒适,防止长久肝气郁结导致的疾病
- 少吃沙拉油, 会导致心血管疾病
- 我国吃猪油有上千年的历史验证, 已经造就出许多百岁人瑞. 有条件吃猪油
- 吃饭不要吃过饱,7~8分饱. 给身体减压, 减轻脏腑的负担
药罐子的中国人
- 高血压的药物控制
- 几乎所有降血压的药都是利尿剂, 会让你的肾功能下降, 而中医认为肾主骨, 其华在发, 开窍在耳, 司记忆, 主先天(寿命多长) , 这就是现在人们会得到骨质疏松症, 老人痴呆症, 掉头发, 听力减退, 寿命变短的原因, 性功能同时下降
- 更且因为西药都是属酸性, 而酸性会破坏血管壁组织, 容易造成血管破裂, 也就是说服用高血压药物的病患将更容易得到中风与心脏病, 不吃的病患反而不会得到这类疾病
- 血糖过高的病人
- 所有的西药都伤害肾脏, 因此服用降血糖的药越多就越容易得到心脏病.
- 中医认为只要肝脏好就不会有眼疾, 根本与高血糖无关, 由于服用西药或注射胰岛素会造成肝脏的损坏因此才会得到青光眼
- 血糖根本没有消失, 多余的血糖就开始屯积在你的脚部, 就好像糖积在杯底一样, 其结果就是双足溃烂, 你等着截肢吧
- 中药都是纯碱性, 在纯碱性的环境里是没有细菌与病毒的, 我们根本没有任何中药会让血糖上升的
- 胆固醇过高的人
- 我在临床上只是让病人停止吃零食三星期, 病人的胆固醇就降下200以上
- 三酸甘油脂过高的人
- 此类问题是因为吃油炸食物过多及过胖造成的
- 我开一些清肝的药给病人,三酸甘油脂就下降了, 因为肝是心之母, 一但肝脏代谢毒素功能下降, 自然有不干净的血进入心脏, 对心脏造成威胁, 从而引发心脏病
- 吃西方多种滋补营养药物的人---这类人是最无知而且愚昧的蠢蛋
- 从未有任何证据显示钙片可以帮助增强人体骨骼, 反而是吃多钙片会使骨骼更脆更容易造成骨质疏松症, 而且副作用是造成肾结石,而维他命C片更烂
- 妇女们服用它的目的是想皮肤美白, 但是结果是多服维他命C片会支援乳癌细胞的成长
- 我们应该多食用天然食物, 有机蔬果绝对是正确的
- 要美白多喝自然的橘子汁最好
- 服用阿斯匹林的人
- 有许多证据显示每天一片阿斯匹林你会有超过85%的机会得到胰脏癌, 因为它是一种强酸剂. 酸性对人体破坏最大
- 碱性体质最好, 不但长寿而且完全没有病痛
- 要成为碱性体质非常简单, 立刻停止喝咖啡不吃甜食, 拒绝冰淇淋可乐, 完全断绝糖果饼干类的零食, 多喝茶, 多吃自然有机蔬果
- 请记住在碱的环境里, 是没有病毒与细菌及癌细胞的
- 胃酸过高反逆食道的人
- 人工糖的颗粒极小, 会如同维他命片一样的喂食细菌及滤过性病毒, 它们吃了之后就排出酸性的粪便, 这就是胃酸的来源
- 服用女性贺尔蒙的太太们要注意
- 常被西医告知要服用贺尔蒙替代品, 否则会得到骨质疏松症, 这些胡说八道的话不知吓傻了多少无知的妇女
- 多吃则会得到骨质疏松症及心脏病乳癌等疾病
- 我从未听说有女人因为更年期不适而死的, 但是我却见到许多女人因为吃女性贺尔蒙而死于心脏病或乳癌的
- 乳房稍有硬块就急着做切片的无知妇女
- 喜欢吃止痛药的人要注意
- 目前市面上所有的止痛药都会伤到肝脏肾脏与心脏的
- 只要肝心肾一受伤, 立刻就会便秘睡不好
- 日子久了就开始掉发, 眼睛视力变差, 体力衰退, 容易抽筋
- 西药营养剂维他命吃多了都会掉发伤肝的(维他命A更是头号肝脏杀手) , 更何况止痛药
- 现在最新的医学研究已经证明了吃止痛药会有中风的危险, 许多刚生完小孩的妇女因为吃止痛药而得到中风
- 常服抗生素的人, 妇女必然小便失禁,男人必然性无能及心脏受损
一些Common Sense
- 健康的人,如果不运动,就会生病。由此可之,生病的人不多运动,结果就是死
- 同气相求,病人绝对不可以孤单独处。当病人住到医院时,必然是跟同样类型的病人住在一起,每天都跟许多无助的眼神对看,想想病人怎么会好呢? 如果是跟家人与亲朋好友住在一起,大家**每天都嘻嘻哈哈的过日子**,许多健康的人在一起,其中只有一个生病的人,其开心气氛当然会影响到病人,让病人常常都忘记自己是病人时,病情就已经好转了
- 找一位住在你家附近的有良心的医师。找到一位好心医师,很关心病人的医师最重要,不需要千里迢迢的找名医治疗,因为这位医师住在你家附近,随时可以提供最关心最贴心你的服务,这点很重要
北派传统中医判断身体是否健康
- 一觉到天亮
- 胃口正常
- 每天早上起床第一件事情就是大便上厕所
- 一天五到七次小便,小便的量大, 颜色要淡黄
- 永远都是头面身体冷, 手脚温热
- 男人女人都有, 叫做早上的阳反应, 女人早上起来的时候, 乳房很敏感, 男人阴茎会勃起
所以你们吃了中药以后, 这六个症状都出来了,代表你的病完全好了. 如果你们吃了中药以后, 本来脚是冷的, 后来变成冰的,就中药无效的明证, 那你们不要再吃中药了,赶快另请高明
女孩子月经期间感冒
还有要记得女孩子在月经的时候得到感冒, 所有的处方都不能用,什么麻黄汤, 桂枝汤, 葛根汤都不能用, 只能用一剂药, 叫小柴胡汤. 因为月经来的时候, 月经往下走, 走到子宫的时候, 正好得到感冒, 感冒的病毒从你外表直接进到子宫,根本不停留于肌表, 这时候桂枝麻黄发不到, 只有用和解的方法, 小柴胡汤一剂下去, 感冒的滤过性病毒跟着你的月经小便一起排出去
感冒辩证诊治
小朋友一感冒, 喉咙痛, 葛根汤症
金枪不倒? 厦门男子勃起2周竟是肺癌作祟.
一个罕见的病例,提醒男性朋友要小心。大陆厦门一位32岁的健壮工人,因为阴茎连续勃起两周疼痛不堪而就医,最后发现是肺癌末期,住院40天后就离开人世。(阴茎部位是肝经所络,属于阴,强直就是实症,二者合并在一起,就是所谓阴实,金匮有云:阴实者死。 )
男性朋友要注意啰!阴茎异常勃起持续时间过长,可别沾沾自喜,小心恶性疾病上身。厦门一名32岁的码头工人,因为连续勃起两周,在小诊所找不出病因,最后因疼痛不堪,到大医院挂急诊,一检查才发现原来是肺癌惹祸。(第一: 西医发现又如何呢?只会死得更快而已,第二: 用中医的五行学说做诊断,就可以了解是金克木,金就是肺。也就是说不做检查就可以知道。 )
肺癌判断
- 第一: 病人于寅时必自动醒来,无法安睡
- 第二: 背后第三椎下有压痛点
- 第三: 耳中肺点必有压痛,而且在同侧,等等这些都是经方家用来确诊是否有肺癌的问题
经方家的保健食品
醒世篇
我写此篇的目的, 是希望有缘读到此篇的读者, 一旦在面临生死决择时, 有多一个想法考虑, 如果因为此篇实际临床案例里的经验而救人一命, 也不枉我一番救世之心, 我将我所亲身经历的医案记录下来, 包含我内心的真实看法, 以及我面临病人为做生死决择时的天人交战的心情. 隐瞒病人名字是尊重个人隐私权, 事实上我的这些病人因为曾经都面对过一次死亡, 现在能够存活下来,他们根本已经不在乎任何事了, 他们连命都敢放在我的手中, 我怎么做或公布姓名他们也决不会反对, 但是尊重隐私权不单是法律更是我的医德, 我将隐瞒病人姓名, 使用代名, 希望读者理解 .
任何有志学习中医的青年才俊请记得, 要成为真正优秀中医不难, 必须精研黄帝内经做为诊断学及病理学的基础, 熟谙伤寒论及金匮的方义, 深研难经中的针灸理论, 多看明朝杨继洲的针灸大成, 犹记今年初收到一本中医学杂志来自美国新英格兰中医学校,它的封面就是一支针的针柄上放置艾草燃烧, 这是传统中医的大忌, 读过针灸大成都知道里面有一篇禁针歌诀写到---针而勿灸灸勿针, 针经为此常叮咛, 庸医针灸一起施, 徒施患者炮烙刑. 自古以来针灸并施一直是禁忌, 这杂志的封面却放上此自以为高明又花俏却不知道让明眼的传统中医一看就知此学校误导美国人的研究中医的心意, 这些人自称为传统中医, 实际上是既非正统中医又非正统西医出身, 嘴上又号称是传统中医, 既误了他人子弟又误导中医学入岐途, 这不是害人是什么? 我一定要告诉群众真正传统中医是什么, 以免大众被误导, 综观我国二十四史,文死谏, 武死战, 古代名臣皆敢冒着被皇帝杀头的生命危险, 直言相劝,务必使皇帝改变想法, 其结果都受到皇帝褒扬的, 我不再乎个人荣辱, 我一定要告诉世界上的无辜人民实话, 真正传统优秀的中医, 只用针与灸及中药的丸,散,膏,丹, 绝对没有用什么电针,雷射针灸,注射针灸之类, 有些更恶劣的中医为求达到效果, 还在中药里加入西药的安眠药及类固醇, 这些都是一些看不好病的中医用来蒙蔽世人的骗术, 害了病人还不算, 甚至还在教学时又误人子弟,真是可悲又可叹.
我写此篇的目的是要解开世人对中医的一大疑问, 就是到底正统优质中医可以治病治到什么程度? 我给大家下个定义,真正的正统中医,不但可以掌握一开始从诊断到治疗到自然恢复健康的全部过程, 并且可以知道如何预防同样的病再次发生.你如果是开业中医, 当你读到这篇时, 照理说你应该很兴奋有如此的医术可以救许多本来不用死的病人才对, 我相信你也可以做到而且甚至比我高明, 只是苦无发表机会, 但是你如果感觉是相反的, 变得很生气, 还要想办法打击我, 是没用的, 因为你根本不是人, 是连乌鸦都不如的蠢蛋, 我为什么如此说呢? 请想想世上有多少人受难于病痛中, 他们本来可以不用死的, 但是因为你从中阻扰, 你无法做到我能做到的, 于是病人冤死在你手上, 你可能不心疼, 因为他只是你的客人, 如果他是你的亲人如父母兄弟妻子等, 也因为你妒忌我而不转诊, 结果也冤死在不应该死的病上, 你仍不知悔改, 仍旧气我, 不气你自己不争气, 不好好多读书加强自己的能力, 不怪自己是学到用时方恨少, 连乌鸦都知道反哺之恩,你都不会, 居然会为了你自己的面子着想, 而眼睁睁的看着你的亲人含冤死去, ,你说你还是人吗?可能你是中医学校的教授, 你的口袋中仍然放着西医的降血压药与降血糖药, 而你口中却在说哪些中药可以降血压哪些可以降血糖,你如果以为你的医术不行别人不知道, 你完全错了, 病人吃了你的药心理很清楚的, 只是没有说出来, 他们只是因为不了解中医到底能够做多少, 有一天他们会知道的, 因为我会不断的写案例, 让世人知道, 总有一日大家会了解的.
我时常因为病人来访, 而中断撰写, 请读者见谅, 我实在忙坏了. 最近我加快速度要完成英文版的伤寒论及金匮, 我尽量赶, 只要ㄧ有时间我就会继续写完它的.
总结:
- 必须精研黄帝内经做为诊断学及病理学的基础
- 熟谙伤寒论及金匮的方义
- 深研难经中的针灸理论.多看明朝杨继洲的针灸大成
禽流感与流感(民众不用惊慌.)
本文转载于 汉唐中医-流行性疾病讨论区-禽流感与流感(10/17/2005)
由于感冒是日常最普遍的疾病,所以单独罗列出来,作为参考
第一:桂枝汤症---病人出现有汗,怕风吹,头痛,有点发烧,肌肉有些酸痛时,就可以服用它,如有咳嗽气喘时加些厚朴杏仁就可以了.
第二:麻黄汤症---病人出现极度怕冷,发烧,身体疼痛,完全无汗时,请立刻服用它.
第三:葛根汤症---中医的寒温之争在此,温病派认为伤寒家没有治温病方,所以只有他们的寒凉药物才可以治温病,这是因为他们没有读通伤寒论导致的,而葛根汤就是经方中治疗温病的处方,病人出现项强,头痛,发热,有汗或是无汗都可以,喉咙痛时,就可以立刻服用它,尤其小孩子几乎都是葛根汤症,因为小孩好动成性,在身体出汗发热时得到的感冒,因此就出现病得自温热,这就是葛根汤症了.
第四: 麻杏甘石汤症---病人咳嗽不止,痰出黄粘,胃口尚好时,可以吃此方.
第五:大青龙汤症---病人出现怕冷,无汗,发烧,咳嗽重,咳出黄痰,身体痛,口渴重,喜喝冷水,没有胃口时,就吃大青龙汤,这就是SARS与禽流感的主要症状.
第六: 小青龙汤症---病人有怕冷,无汗,发烧,咳嗽重,出白痰,无渴,身体痛,没有胃口时,就可以用它了.
第七:小柴胡汤症---病人忽冷忽热,加上呕心,胸胁苦满时,请服用此方,还有女子月经期来时正好得到感冒,就喝此药,如有咳嗽气喘时加些厚朴杏仁就可以了.
第八: 大柴胡汤症---如果病人出现便秘,又有忽冷忽热,胸胁苦满,兼有发烧此时请用大柴胡汤.
原文如下:
禽流感与流感(10/17/2005)
这波禽流感已经被西药厂利用来威胁民众的生命,其目的就是想赚大钱,但是使用的手段非常之恶劣,吃像非常难看,我有必要跟民众说清楚讲明白,以解除民众的忧心与疑虑,请大家安心愉快的过日子,我先归类西药厂最惯用的手段给大家看.
首先他们在事前先使用毫无根据的数据,夸大死亡人数,其目的第一是要民众开始害怕,如果卫生署不理会西药厂时,民众就会怪政府,然后政府只好向西药厂屈服,去购买根本没用的疫苗与抗病毒的药,第二是当感染期过了,如果很少人死于流感,他们就说是疫苗有效,是抗病毒药物有效,如果还是死很多人,他们就会说是执行不当或是有别的感染源或是新变种病毒造成疫苗无效的,所以总之与他们是无关,反正好坏都是他们在自导自演中,民众是永远被隐瞒在鼓里,而他们也知道民众在事后是不会关心的,大家只在乎自己没有死,这就是他们最了解的人性弱点,因此他们一直在骗人而无人去揭穿他们.这是个世纪大骗局,目前正在上演中,中医认为百病风之始,感冒当然是问题,但是中医老早在二千前年以前已经将此问题解决了,但是中国人却不知道,居然还听信外国人的骗局,真是祸国殃民的大骗局. 这些专门以威胁手段来欺骗海峡两岸中国人的西药厂,都将名列我的黑名单中,他们将是我第一个要消灭的目标,我看看谁敢威胁我们中国人,非修理他们不可,哪天这些人得到时癌症落到我的手上,他们就知道厉害了,这次简直把我气炸了,赶快吃点中药消消火气去.
亲爱的海峡两岸台湾与大陆民众们,大家不要惊慌,这一波的流行性感冒因为西药厂的利益介入,已经造成民众的恐慌,由于民众是无知与无辜的,所以有必要替民众解决这种疑虑恐慌,我国自古以来就有流感,汉朝医圣张仲景就是因为流感造成整个张氏家族损失三分之二的人口,因而他辞去南阳太守的职务,发奋图强研究医学,于是写下了名垂千古的伤寒杂病论就是经方,我使用经方至今从感冒到癌症,一一好转,尤其是治感冒时常都是一剂就好转,千年以来经方一直都是如此之快,孰知今日出现个西药厂,它们不断的制造疾病,不断的为打击人体抵抗力而不遗余力,因为只有当人体的抵抗力变差后才会生病,才会容易感冒,这样他们才有钱赚,他们希望全世界的人通通都生病,他们才高兴,所以他们一直鼓励西医使用各种抗生素与止痛药,打各种害人的疫苗,建议民众多吃害人的维他命,于是多年以后民众身体就越来越差了,不但很容易得到感冒,因为民众的免疫系统已经被西药破坏尽了,更且会只因为得到小感冒就出人命,这是个天大的笑话,为了全民福祉着想,我誓言一定要终结西药厂,让我们的下一代生活的健康快乐,永远免除来自疾病的威胁,现代人类最严重的癌症是来自西药厂不是来自人体,不清除它,民众将永远没有平安的日子可过,永远生活在这阴影威胁之下的.
现在由汉唐中医为民众解决这问题吧,民众只要记住以下很简单的辨症法,然后依照这法则选用药物,而这些药物都是台湾与中国大陆的国家卫生署自己核准的药物,但是因为他们都是西医所以他们不会用,因此这药是由不懂得使用的人来核准的,现在请大家一起跟我进入经方的世界.
第一:桂枝汤症---病人出现有汗,怕风吹,头痛,有点发烧,肌肉有些酸痛时,就可以服用它,如有咳嗽气喘时加些厚朴杏仁就可以了.
第二:麻黄汤症---病人出现极度怕冷,发烧,身体疼痛,完全无汗时,请立刻服用它.
第三:葛根汤症---中医的寒温之争在此,温病派认为伤寒家没有治温病方,所以只有他们的寒凉药物才可以治温病,这是因为他们没有读通伤寒论导致的,而葛根汤就是经方中治疗温病的处方,病人出现项强,头痛,发热,有汗(更正一点:或是无汗都可以,我忽略掉这一点了),喉咙痛时,就可以立刻服用它,尤其小孩子几乎都是葛根汤症,因为小孩好动成性,在身体出汗发热时得到的感冒,因此就出现病得自温热,这就是葛根汤症了.
第四: 麻杏甘石汤症---病人咳嗽不止,痰出黄粘,胃口尚好时,可以吃此方.
第五:大青龙汤症---病人出现怕冷,无汗,发烧,咳嗽重,咳出黄痰,身体痛,口渴重,喜喝冷水,没有胃口时,就吃大青龙汤,这就是
SARS与禽流感的主要症状.
第六: 小青龙汤症---病人有怕冷,无汗,发烧,咳嗽重,出白痰,无渴,身体痛,没有胃口时,就可以用它了.
第七:小柴胡汤症---病人忽冷忽热,加上呕心,胸胁苦满时,请服用此方,还有女子月经期来时正好得到感冒,就喝此药,如有咳嗽气喘时加些厚朴杏仁就可以了.
第八: 大柴胡汤症---如果病人出现便秘,又有忽冷忽热,胸胁苦满时,兼有发烧此时请用大柴胡汤.
以上八个经方是我国使用近二千年之有效处方治疗感冒,处方至今从未变更过,时常都是一剂知,二剂已的,民众只需按照上面所陈述的症状,就可以自行判定你自己或是亲人需要吃什么药了,保证当天就好了,不需要经过医师处方,反正他们也不会用,你去问他们也是白问,现在只能自求多福了,因为你们的卫生署不知道他们自己已经核准的科学中药如此之好,所以他们不知道如何教导民众,因此只好由我来代劳了,如果民众按照我的指示吃药仍然没好,请传真给我, 1 -321-454-9974 ,我一定替你治疗的,感冒会死人吗??? 真是让人笑掉大牙的事.传真时请说明你的症状,发烧?体痛?胃口?有无口渴?喜欢喝热水还是冷水?有无出汗?怕冷?怕热?有无咳嗽?咳出清痰还是黄痰?有无便秘? 读者只要说明清楚发病症状及病人体格大小等资料,并且请附上回传号码,我将立刻回传处方给你,你们自行去中药行买药就可以了,完全免费服务,我保证将你救回来的,但是你如果是因为笨,因注射疫苗之后才发生的感冒,恕我不治,因为你实在太笨了,少些笨蛋,政府就少些开销的.
如何证明上面的中药绝对有用呢? 很简单,读者请买一些上面我说的药与克流感西药,然后去公园或是养鸡场,将中药与西药洒在地上,读者就会看到这些禽类将选择中药吃,绝对没有一只笨鸡或是笨鸟会去选择西药克流感吃的,这就是Mother Nature,就好像是当你家的猫或狗有病时,它们会去吃草,自己去找寻能够治病的药物,绝对不会去吃西药的,除非动物医师硬注射西药入体内,否则它们绝对不吃西药的,读者也可以将这两种药放在餐桌上过一夜,第二天早上你就会发现你家的蟑螂只吃中药,没有一只笨蟑螂会去吃克流感的,这就是蟑螂可以生存在地球十亿年以上而不被毁灭的真正原因,因为它们比人类聪明太多了,连他们都知道如何做选择.
给疾病管制局的建议,请你们去购买桂枝汤与大青龙汤,将它们分开做两堆,置于户外,当你们看到有鸟类来吃大青龙汤时,这些就是被感染到禽流感的鸟,去吃桂枝汤的鸟就是没有得到禽流感的,此法也可以用在养鸡场,禽类吃了大青龙汤之后会排粪便出来,此时你们就可以去取些样本来化验,就知道我对否? 根本不需要赶尽杀绝的,这是削足适履的行为.
大青龙汤处方如下: 麻黄三钱杏仁五钱石膏八钱炙甘草五钱桂枝五钱生姜二片红枣十二枚打碎(有做过心脏手术的病人不可以用麻黄,请改用荆芥五钱,防风三钱,浮萍三钱来取代麻黄.)
用六碗水大火快煮成二碗,汤成后立刻关火,待温时空腹喝第一碗,如果一小时内汗出烧退咳止,就不须要喝第二碗,如果三小时内无出汗,就再喝第二碗,汗出时就不用再喝了,当身体出汗时须待静室中,等到出汗自然停止后,再出房间,切不可以出汗时吹到风,如此病毒将无法排尽,还会再发的. 成人每次一碗,小孩每次半碗,婴儿每次四分之一碗. 记住一旦汗出,就不用再喝第二碗了,因为已经好转了,再喝恐怕伤到津液. 一般病人在服药后第二天中午时会很饿,胃口大开,这表示正常了.
一般市面上的科学中药成药,大家也可以去买仙丰GMP厂制造的很好用,这点卫生署还做的不错. 如果有民众真正得到了禽流感,西药是肯定失效的,当此生死存亡之时如果医师的态度是宁可眼睁睁的看到病人死去,也不给病人一丝生存机会不让病人服用经方时,你告诉卫生署是没用的,他们官官相护,所以请知道的人写传真给我,我统一集中起来一起骂,并且将他们打入恶质医师的行列,我必将让这些恶质医师遗臭万年,永世不得翻身,反正真正恶医师都知道我是谁,我也不担心他们怎么对付我,因为我比他们还会治病,之所以会如此是因为他们一直在专门研究如何吓病人,这是他们专业所在,而我却是一直在研究如何治疗疾病,而这却是我的专业所在,所以只有我能威胁他们,他们无法威胁我的,他们生病时也只有我知道如何救他们,读者说他们遇到我时该怎么办呢?早就说过了,我是鬼见愁,只有心里有鬼的才会真正愁我,真有佛心之人怎会愁我呢?
此篇论文欢迎大家引用,济世救人是我辈职责所在,请大家告诉大家.但是要注明出处,谢谢.
美国汉唐中医倪海厦撰写于佛州
以下是经典方剂与现代中成药的对应关系:没有经过验证
-
桂枝汤: 现代中成药: 桂枝颗粒、桂枝合剂 功效: 解肌发表,调和营卫,用于外感风寒表虚证。
-
麻黄汤: 现代中成药: 麻黄碱片、感冒通片 功效: 发汗解表,宣肺平喘,用于外感风寒所致的咳嗽、气喘。
-
葛根汤: 现代中成药: 葛根解表颗粒、葛根汤颗粒 功效: 解肌退热,生津,用于外感风寒、项背强痛、无汗等症。
-
麻杏甘石汤: 现代中成药: 麻杏甘石合剂、清肺抑火丸 功效: 宣肺泄热,止咳平喘,用于肺热咳嗽、喘息等症。
-
大青龙汤: 现代中成药: 大青龙颗粒 功效: 发汗解表,清热除烦,用于外感风寒、内有郁热的症状。
-
小青龙汤: 现代中成药: 小青龙颗粒、小青龙口服液 功效: 解表散寒,温肺化饮,用于外感风寒,内有水饮的咳嗽、喘息。
-
小柴胡汤: 现代中成药: 小柴胡颗粒、小柴胡口服液 功效: 和解表里,用于少阳证,如寒热往来、胸胁苦满、心烦喜呕等。
-
大柴胡汤: 现代中成药: 大柴胡颗粒 功效: 和解少阳,内泻热结,用于少阳阳明合病,或肝胆热实,胃肠积滞等。
MySQL服务器常用操作
创建一个数据库
CREATE DATABASE nextcloud CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
创建用户并授权
CREATE USER 'nextcloud_user'@'%' IDENTIFIED BY 'your_password';
GRANT ALL PRIVILEGES ON nextcloud.* TO 'nextcloud_user'@'%';
FLUSH PRIVILEGES;
注意事项
- 性能影响
utf8mb4_bin因为逐字符比较和区分大小写,性能可能略低于utf8mb4_general_ci。- 选择排序规则时需要在性能和功能之间权衡。
- 文件系统的影响
即使数据库支持大小写敏感排序,文件系统(如
ext4、NTFS)可能不区分大小写,这可能导致文件名冲突。
总结
- 默认选择:
utf8mb4_general_ci,除非明确需要区分大小写。 - 如果需要大小写敏感,使用
utf8mb4_bin。 - 区分大小写的需求较为少见,但在文件名敏感的场景中可能是必要的。
MySQL-常用语句记录
按照子表的id升序查询出子表字段去重并且逗号隔开
GROUP_CONCAT(DISTINCT column_name ORDER BY column_name SEPARATOR ',')
举例
-
b.xxx 的值不区分大小写 select a.*, GROUP_CONCAT(DISTINCT b.xxx ORDER BY b.id ASC SEPARATOR ',') as bxxx from order a left join detail b a.id= b.o_id group by a.id
-
b.xxx的值区分大小写 select a.*, GROUP_CONCAT(DISTINCT BINARY b.xxx ORDER BY b.id ASC SEPARATOR ',') as bxxx from order a left join detail b a.id= b.o_id group by a.id
count(1) count(*) 和 count(name)的区别
count(1)和count(*)
在 MySQL 中,COUNT(*) 和 COUNT(1) 通常是等价的,因为它们都用来计算表中的行数,并且在大多数情况下,它们的性能和结果是一样的,且性能差异微乎其微
SELECT COUNT(*) FROM table;
SELECT COUNT(1) FROM table;
count(name)
- 功能: 计算 name 列中非 NULL 的行数。如果 name 列包含 NULL 值,则这些 NULL 值不会被计入。
- 性能: 由于需要考虑 name 列的 NULL 值,因此在某些情况下,性能可能会略逊色于 COUNT(*),但差别通常不大。
总结: 在大多数情况下,COUNT() 和 COUNT(1) 在 MySQL 中表现一致,你可以使用它们中的任何一个来计算行数。不过,**COUNT() 通常是更直观和推荐的选择**。
数据同步差异排查
场景: 从A库同步一张表A1到B库的B1, A表总共30001,B表30000条.找出没有同步过去的那一条
方案是查询出A表的所有ID,然后把所有id UNION ALL,在进行两个表的关联
SELECT ids.id
FROM (
SELECT 1 as id
UNION ALL SELECT 43581
UNION ALL SELECT 43583
.... 假设中间还有n条
UNION ALL SELECT 43607
UNION ALL SELECT 43609
) AS ids
left join shop_new ds on ds.id = ids.id
where ds.id is null
;
通过叶子结点找到上级树
返回的结果包含blood_id = 23的数据行
用途是, 通过叶子节点找所有上级,然后封装成链表的形式,代码相对复杂.所以可以换一个思路,先通过以下SQL找到上级树.然后从parent_id集合中排除blood_id集合,得到first_prent_id集合,表示当前节点所在上级树的第一层节点的id集合
然后遍历first_prent_id集合,通过Java查询以下的SQL的结果集中, 父id为**first_prent_id.get(i)**的数据,则取到了当前节点的下一级节点列表.
WITH RECURSIVE ancestors AS (
SELECT id,blood_id,parent_id FROM blood_tree WHERE blood_id = 23
UNION
SELECT p.id,p.blood_id,p.parent_id FROM blood_tree p
JOIN ancestors a ON p.blood_id = a.parent_id
)
select * from ancestors;
解释:
-
CTE 表示递归表达式
-
WITH RECURSIVE ancestors AS (...)定义了一个名为ancestors(可以自定义)的递归 CTE -
表达的意思是:
- 以blood_id = 23的数据行row1为参考,查询所有
blood_id=row1.parent_id的数据行rowM - 然后继续对rowM的每一行数据, 进行递归,查询
blood_id=rowM.parent_id的所有数据行 - 最后将这些数据UNION在一起.得到关于某个叶子节点的上级树
- 以blood_id = 23的数据行row1为参考,查询所有
完整的Java代码如下:
private List<BloodNodeResVo> getParentBloods(Integer bloodId) {
List<BloodNodeResVo> treeList = new ArrayList<>();
List<PtBloodTree> bloodTreeList = ptBloodTreeService.getParentTreeByBloodId(bloodId);
if (CollectionUtils.isEmpty(bloodTreeList)) {
return treeList;
}
//包括每一层的父节点
Set<Integer> parentIds = bloodTreeList.stream().map(PtBloodTree::getParentId).collect(Collectors.toSet());
//包括每一层的子节点
Set<Integer> bloodIds = bloodTreeList.stream().map(PtBloodTree::getBloodId).collect(Collectors.toSet());
//所有节点.用于后期批量一次性查SQL.
Set<Integer> allBloodIds = new HashSet<>();
allBloodIds.addAll(parentIds);
allBloodIds.addAll(bloodIds);
//父节点中移除所有的叶子节点.因为第一层的节点不再有父节点.所以第一层的节点也就不存在于子节点中
parentIds.removeAll(bloodIds);
List<PtBloodIdx> ptBloodIdxes = listByIds(allBloodIds);
Map<Integer, PtBloodIdx> bloodIdxMap = Optional.ofNullable(ptBloodIdxes).orElse(new ArrayList<>()).stream().collect(Collectors.toMap(PtBloodIdx::getId, Function.identity(), (k1, k2) -> k1));
//遍历第一层的节点
for (Integer parentId : parentIds) {
PtBloodIdx ptBloodIdx = bloodIdxMap.get(parentId);
BloodNodeResVo bloodNodeResVo = new BloodNodeResVo();
bloodNodeResVo.setBloodId(ptBloodIdx.getId());
bloodNodeResVo.setBloodName(ptBloodIdx.getBloodName());
bloodNodeResVo.setNumber(1);
treeList.add(bloodNodeResVo);
//获取子节点
getChild(bloodTreeList, bloodNodeResVo, bloodIdxMap);
}
return treeList;
}
void getChild(List<PtBloodTree> bloodTreeList, BloodNodeResVo parent, Map<Integer, PtBloodIdx> bloodIdxMap) {
bloodTreeList.stream().filter(p -> p.getParentId().equals(parent.getBloodId())).forEach(p -> {
PtBloodIdx bloodIdx = bloodIdxMap.get(p.getBloodId());
BloodNodeResVo child = new BloodNodeResVo();
child.setBloodId(bloodIdx.getId());
child.setBloodName(bloodIdx.getBloodName());
parent.getChilds().add(child);
//递归调用子节点的子节点
getChild(bloodTreeList, child, bloodIdxMap);
});
}
通过父节点找到所有子下级树
返回的结果包含blood_id = 23的数据行
WITH RECURSIVE descendants AS (
SELECT blood_id,parent_id,blood_level FROM blood_tree WHERE blood_id = 23
UNION
SELECT p.blood_id,p.parent_id,p.blood_level FROM blood_tree p
JOIN descendants a ON p.parent_id = a.blood_id
)
select * from descendants;
Java基础-易错点
List.remove
注意有两个重载方法remove(int)和remove(Object), 很容易混淆
案例:
Map<String, Integer> unionMap = new HashMap<>();
for (int i = 0; i < insertList.size(); i++) {
CstGoods cstGoods = insertList.get(i);
String unionKey = String.join("_", cstGoods.getSpCode(), cstGoods.getCostType(), String.valueOf(cstGoods.getCostScene()), cstGoods.getBgDate().toString(), cstGoods.getEdDate().toString());
if (unionMap.containsKey(unionKey)) {
unionMap.put(unionKey, i);
//特别注意这一行
Integer index = unionMap.get(unionKey);
insertList.remove(index);
i--;
} else {
unionMap.put(unionKey, i);
}
}
本意是移除已经存在的列. 但是问题就出在list.remove. 如果remove方法的入参传入的是包装类型,自然就会执行remove(Object), 那么结果肯定是移除不了这个重复对象. 所以需要将Integer index = unionMap.get(unionKey); 改为 int index = unionMap.get(unionKey);.要不然会导致死循环
修正后的代码
Map<String, Integer> unionMap = new HashMap<>();
for (int i = 0; i < insertList.size(); i++) {
CstGoods cstGoods = insertList.get(i);
String unionKey = String.join("_", cstGoods.getSpCode(), cstGoods.getCostType(), String.valueOf(cstGoods.getCostScene()), cstGoods.getBgDate().toString(), cstGoods.getEdDate().toString());
if (unionMap.containsKey(unionKey)) {
unionMap.put(unionKey, i);
//特别注意这一行
int index = unionMap.get(unionKey);
insertList.remove(index);
i--;
} else {
unionMap.put(unionKey, i);
}
}
Java 8 Stream API 之 removeIf
removeIf简化代码
- 移除所有负数
List<Integer> numbers = Arrays.asList(1, -2, 3, -4, 5);
numbers.removeIf(n -> n < 0);
// 结果: [1, 3, 5]
- 移除过期的订单
List<Order> orders = getOrders(); // 获取订单列表
orders.removeIf(order -> order.getExpiryDate().isBefore(LocalDate.now()));
// 移除所有过期的订单
- 移除名称重复的用户
List<UserDTO> users = getUsers();
if (CollectionUtils.isNotEmpty(users)) {
Set<String> uniqueNames = new HashSet<>();
users.removeIf(u -> !uniqueNames.add(u.getName()));
}
return users;
Java 8 Stream API 之 map
- map简化代码
//简化前
Map<Integer, PtBloodIdx> bloodIdxMap = listByIds(bloodIds).stream().collect(Collectors.toMap(PtBloodIdx::getId, Function.identity(), (k1, k2) -> k1));
for (PtBloodTree ptBloodTree : trees) {
Integer bloodId = ptBloodTree.getBloodId();
PtBloodIdx ptBloodIdx = bloodIdxMap.get(bloodId);
if (ptBloodIdx == null) {
continue;
}
ChildBloodTreeResVo res = new ChildBloodTreeResVo();
res.setId(ptBloodIdx.getId());
res.setBloodCode(ptBloodIdx.getBloodCode());
res.setBloodName(ptBloodIdx.getBloodName());
resList.add(res);
}
retrun resList;
//简化后
return trees.stream()
.map(tree -> bloodIdxMap.get(tree.getBloodId()))
.filter(Objects::nonNull)
.map(ptBloodIdx -> {
Integer bloodId = .getId();
List<BloodNodeResVo> parentBloods = getParentBloods(bloodId);
return ChildBloodTreeResVo.builder().id(bloodId).bloodCode(ptBloodIdx.getBloodCode()).bloodName(ptBloodIdx.getBloodName()).parentBloods(parentBloods).build();
})
.collect(Collectors.toList());
解释:
- 通过第一个.map直接从tree转换成了PtBloodIdx
- filter过滤后,只保留每一个不为null的对象
- 第二个map开始组装最终的结果里的每一个对象
小技巧
文件拆分
将一个文件按照1000行拆分成一个新文件
场景: 一个文件中存在1万个ID,数据库每次in的时候只能查询1000个, 于是需要1000个ID作为一次拆分
打开git bash, 执行以下命令
# 1000表示1千行作为一次拆分, 文件保存在abc目录下, 新文件的前缀是shop_1000_
split -l 1000 shopIds.groovy abc/shop_1000_
每100KB拆分成一个新文件
split -b 100k shopIds.groovy abc/shop_1000_
Git常用操作
还原至master
--mixed和--hard
git reset 右面可选{--mixed, --hard}, 两者有本质的区别. --mixed是默认的
| 操作 | git reset --hard origin/master | git reset --mixed origin/master |
|---|---|---|
| HEAD | 重置为 origin/master 指向的提交 | 重置为 origin/master 指向的提交 |
| 暂存区(staging area) | 重置为远程 origin/master 的状态,丢弃所有已暂存的更改 | 重置为远程 origin/master 的状态,丢弃所有已暂存的更改 |
| 工作目录(working directory) | 恢复为远程 origin/master 的状态,丢弃所有未提交的更改 | 保留本地修改,但将其恢复为“未暂存”状态,不会丢失工作目录中的更改 |
两者的相同点:
- 都是为了把未推送到远程的代码状态还原到和远程状态
- 执行好,新增的文件,会回退到未暂存的状态,不会被删除.
- 删除的话需要执行
git clean -fd,谨慎操作.执行后,本地未推送到远程的代码将会彻底丢失-f表示强制删除-d表示删除未跟踪的目录
- 删除的话需要执行
两者的本质区别:
--mixed是默认的, 操作比较柔和一点,还原后,项目的提交记录和远程保持一致了.但是本地已修改的代码不会丢弃.未推送到远程的代码代码还在本地,只是提交记录和远程保持一致了--hard不是默认的,需要指定, 操作很强硬, 执行后, 本地的已修改未推送到远程的代码会彻底丢弃
阿里云-数据服务概述-学习笔记
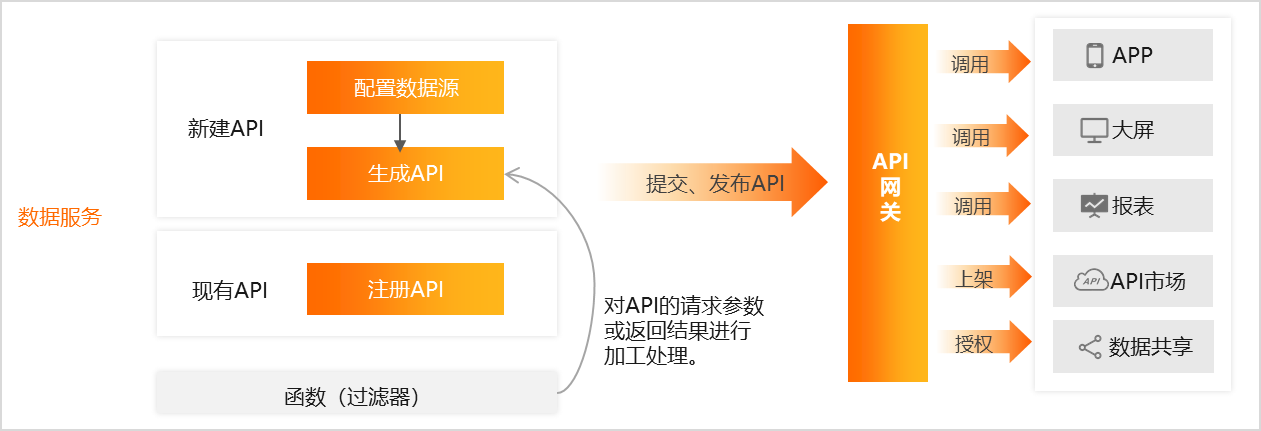
以下内容,大量引用于 阿里云
DataWorks数据服务模块是一个灵活轻量、安全稳定的数据API构建平台
- API构建平台
- 已有的API注册至平台统一管理
- 注册生成API
相关概念
- API(Application Programming Interface , 应用程序编程接口):API是让应用、软件、系统能够面向数据源进行数据交互的接口,数据服务API支持“读数据”的操作,可以从数据库、数据表中不断地进行数据查询。
- 函数:作为API过滤器,对API的请求参数或返回参数进行加工处理。当使用函数作为API过滤器时,前置过滤器和后置过滤器的函数类型需要保持一致,暂不支持对同一API的前置和后置过滤器选择不同的函数类型。
API分组
API分组是指针对某一个功能或场景的API集合,也是API网关对API的最小管理单元。在阿里云API市场中,一个API分组对应于一个API商品。
一个业务流程下可以有多个API分组
- 您需要确保当前业务流程下,无文件夹、API、函数和服务编排等其它文件,才能够成功删除业务流程。
- 如果业务流程内存在其它文件,请您先删除所有的文件,再删除该业务流程。
数据服务错误代码表
| 错误代码 | 描述 | 语义 |
|---|---|---|
| 0 | success | 数据查询及返回结果成功。 |
| 1108110583 | query timeout | 请求查询超时,API在数据服务和数据库中的整体执行时长超过了API环境配置中所设置的超时时间,导致请求超时。 |
| 1108110519 | param miss | 请求参数缺失,当API设置了必填的请求参数,但实际请求中存在必填参数未传参。 |
| 1108110584 | api context failed | 依赖第三方获取上下文失败,上下文信息包括:数据源连接信息、数据源AK信息、租户信息等。 |
| 1108110622 | datasource query error | 查询数据源失败,可能原因包括:SQL语法错误、数据源未在系统内置10s超时上限内返回执行结果、超过数据源连接数限制等。 |
| 1108110703 | database connection error | 数据源连接失败。 |
| 1108113002 | rate limit | API调用达到阈值上限,已被系统限流。目前API调用均使用公共服务资源组,公共服务资源组的阈值约为每租户200 QPS,超出该阈值将触发调用流量控制。 |
数据推送
将数据推送至Webhook
- 通过简单配置,实现定期将所需的业务数据推送至多个不同的Webhook
- 支持的推送渠道:钉钉群、飞书群、企业微信群以及Teams
数据推送服务使用限制
- 数据推送功能推送至不同对象时的数据大小限制:
- 推送目标为钉钉,推送数据大小不超过20KB。
- 推送目标为飞书,推送数据大小不超过20KB,图片小于10MB。
- 推送目标为企业微信,每个机器人发送的消息不能超过20条/分钟。
- 推送目标为Teams,推送大小不大于28KB。
| 功能分类 | 功能点 | 向导模式 | 脚本模式 |
|---|---|---|---|
| 查询对象 | 单数据源、单数据表查询 | 支持 | 支持 |
| 单数据源、多数据表关联查询 | 不支持 | 支持 | |
| 查询条件 | 数值型等值查询 | 支持 | 支持 |
| 数值型范围查询 | 支持 | 支持 | |
| 字符型精确匹配 | 支持 | 支持 | |
| 字符型模糊匹配 | 支持 | 支持 | |
| 查询结果 | 字段值原样返回 | 支持 | 支持 |
| 字段值进行数学运算 | 不支持 | 支持 | |
| 字段值进行聚合函数运算 | 不支持 | 支持 | |
| 返回结果分页 | 支持 | 支持 | |
| 查询逻辑 | mybatis标签 | 不支持 | 支持 |
API安全
IP白名单
如100.64.0.0/10,11.193.102.0/24
生成API
| 参数 | 描述 |
|---|---|
| API模式 | 包括向导模式和脚本模式,此处选择向导模式。 |
| API名称 | 支持中文、英文、数字、下划线(_),且只能以英文或中文开头,4~50个字符。 |
| API Path | API存放的路径,即相对于服务host,API的请求路径。例如/user。说明支持英文、数字、下划线(_)和连字符(-),且只能以( /) 开头,不得超过200个字符。 |
| 协议 | 支持HTTP和HTTPS。如果您需要通过HTTPS协议调用API,请您发布API至网关后,在API网关控制台绑定独立域名,并上传SSL证书。详情请参见支持HTTPS。 |
| 请求方式 | 支持GET和POST。说明当请求方式选择GET时,请求参数位置仅支持选择QUERY。当请求方式选择POST时,请求参数位置支持选择QUERY和BODY。 |
| 返回类型 | 仅支持JSON返回类型。 |
| 可见范围 | 包括工作空间和私有:工作空间:该API对本工作空间内的所有成员可见。私有:该API仅对API的负责人可见,且暂不支持授权。说明如果设置可见范围为私有,在目录树中,仅自己可见,工作空间内的其他成员不可见。 |
| 标签 | 从标签列表中选择相应的标签,详情请参见创建及管理API标签。说明标签名称支持汉字、英文、数字和下划线(_),您最多可以设置5个标签,且每个标签不超过20个字符。 |
| 描述 | 对API进行简要描述,不得超过2000个字符。 |
| 目标文件夹 | 存放API的目录,可以在下拉列表选择已创建的业务流程,选定后,会生成API的存放路径。默认格式为:“业务流程/业务流程名称/API”,例如业务流程/ceshi/API。 |
后续会有一堆正则表达式, 建议用枚举管理起来
麻雀虽小,五脏俱全. 建议脏腑分明
配置过滤器
对入参和出参,进行二次加工
设置是否返回结果分页
在高级配置区域,设置是否返回结果分页。
- 如果不开启返回结果分页,则API默认最多返回2000条记录。
- 如果返回结果可能超过2000条,请开启返回结果分页功能,开启后,您可以进入右侧导航栏的服务资源组页面,根据资源组类型设置单页条数上限。
说明
当数据服务的API在编辑页面右侧导航栏的返回参数已经开启了返回结果分页,如果您在该API编辑页面的编写查询SQL区域,使用SQL语句配置了limit限制(即返回结果的条数限制),则该limit限制不生效,返回结果的条数限制仍然会以返回结果分页的配置内容为准。
开启返回结果分页后,会自动增加以下公共参数:
-
公共请求参数
- returnTotalNum:用于确定单次请求中是否要返回数据总条数。
- pageNum:当前页号。
- pageSize:页面大小,即每页记录数。
-
公共返回参数
- pageNum:当前页号。
- pageSize:页面大小,即每页记录数。
- totalNum:总记录数。
记录操作日志
什么时间,谁, 做了什么事情
通过条件控制返回结果按照不同的表字段进行排序
这块可以设计页面,按照设置的字段顺序排序. 页面支持切换顺序?????
- 当
var的值为1时,使用order by col01对结果进行排序。 - 当
var的值为2时,使用order by col02对结果进行排序。 - 当
var的值为3时,使用order by col01,col02对结果进行排序。 - 当
var的值为4时,使用order by col02,col01对结果进行排序。
注册API
入参
| 参数 | 描述 |
|---|---|
| API名称 | 支持中文、英文、数字、下划线(_),且只能以英文或中文开头,4~50个字符。 |
| API Path | API存放的路径,例如/user。说明支持英文、数字、下划线(_)和连字符(-),且只能以( /) 开头,不得超过200个字符。 |
| 协议 | 支持HTTP、HTTPS协议。如果您需要通过HTTPS协议调用API,请您发布API至网关后,在API网关控制台绑定独立域名,并上传SSL证书。详情请参见支持HTTPS。 |
| 请求方式 | 支持GET、POST、PUT和DELETE。 |
| 返回类型 | 支持JSON和XML。 |
| 可见范围 | 包括工作空间和私有:工作空间:该API对本工作空间内的所有成员可见。私有:该API仅对API的负责人可见,且暂不支持授权。说明如果设置可见范围为私有,在目录树中,仅自己可见,工作空间内的其他成员不可见。 |
| 标签 | 从标签列表中选择相应的标签,详情请参见创建及管理API标签。说明标签名称支持汉字、英文、数字和下划线(_),您最多可以设置5个标签,且每个标签不超过20个字符。 |
| 描述 | 对API进行简要描述,不得超过2000个字符。 |
| 目标文件夹 | 存放API的目录。 |
出参
| 参数 | 描述 |
|---|---|
| 后台服务Host | 待注册API服务的Host,以**http://或https://**开头,并且不包含Path。说明示例:假设您接口服务地址为http://xxx-cn-xxx.alicloudapi.com/user/info,可取http://xxx-cn-xxx.alicloudapi.com设为后台服务Host。具体的可根据您接口服务地址实际路径进行配置。 |
| 后台服务Path | 待注册API服务的Path,Path中支持参数,参数要放在**[]中,如/user/[userid]**。配置Path中的参数后,在注册API向导的第二步API参数配置环节,系统会自动在请求参数列表添加Path位置的参数。说明示例:假设您接口服务地址为http://xxx-cn-xxx.alicloudapi.com/user/info,可将/user/info设为后台服务Path。具体的可根据您接口服务地址实际路径进行配置。 |
| 后端超时 | 设置后端超时时间。 |
需要接口请求链路,查看接口详情
API请求统计: ES
Aviator函数和正则表达式 适用场景对比
| 场景 | 正则表达式 | Aviator |
|---|---|---|
| 简单的字符串匹配和验证 | ✔️ 非常适合 | ❌ 过于复杂,不推荐使用 |
| 动态规则修改 | ❌ 不支持 | ✔️ 支持动态加载规则 |
| 多条件逻辑 | ❌ 难以实现,表达式冗长且复杂 | ✔️ 支持多条件逻辑 |
| 规则与代码分离 | ❌ 不支持 | ✔️ 规则可以存储在外部配置 |
| 可读性要求高 | ❌ 正则表达式难以理解 | ✔️ 表达式更易于理解 |
| 扩展性要求高 | ❌ 仅限于正则的能力 | ✔️ 支持复杂逻辑、动态函数调用 |
大数据与实时分析
Flink_CDC同步MySQL到StarRocks初体验
安装flink
建议搭建初期, 使用官网提供的flink cdc sql在sql-client.sh中测试,根据错误提示添加对应的包
mkdir -p /app
wget https://archive.apache.org/dist/flink/flink-1.19.1/flink-1.19.1-bin-scala_2.12.tgz
tar -zxvf flink-1.19.1-bin-scala_2.12.tgz
cd flink-1.19.1
echo "execution.checkpointing.interval: 3000" >> /app/flink-1.19.1/conf/config.yaml
cd /app/flink-1.19.1/lib
# flink 1.19推荐下载3.3.0 connector包,如果直接使用flink,不使用dinky,完全没问题
# 由于我这边使用的dinky是1.2.3版本,3.3.0 connector包不兼容. 所以使用测试通过的包,如下
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.1.0/flink-sql-connector-mysql-cdc-2.1.0.jar
chmod +rwxrwxrwx flink-sql-connector-mysql-cdc-2.1.0.jar
wget https://repo1.maven.org/maven2/com/starrocks/flink-connector-starrocks/1.2.10_flink-1.19/flink-connector-starrocks-1.2.10_flink-1.19.jar
chmod +rwxrwxrwx flink-connector-starrocks-1.2.10_flink-1.19.jar
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.27/mysql-connector-java-8.0.27.jar
chmod +rwxrwxrwx mysql-connector-java-8.0.27.jar
# 至此, 依赖包齐活
# flink默认是localhost访问,如果要允许其他IP访问.
# 需要修改 bind-host: localhost,localhost改为0.0.0.0 多处需要修改
# 需要修改 rest下的address为0.0.0.0
# 启动flink,执行1次增加1个task slot, 可以多次执行
# 每次启动的task slot 可以在config/config.yaml文件中修改numberOfTaskSlots的值
/app/flink-1.19.1/bin/start-cluster.sh
# 至此,flink准备完毕
安装MySQL和starrocks
docker-compose.yml
version: '2.1'
services:
StarRocks:
image: starrocks/allin1-ubuntu:3.2.6
environment:
# 如果没有指定密码,启动后进入容器后,执行ALTER USER 'root' IDENTIFIED BY 'eishees4saez3kaepei3Yi8am2oonguG';进行修改也行
- STARROCKS_ROOT_PASSWORD=eishees4saez3kaepei3Yi8am2oonguG
ports:
- "8080:8080"
- "9030:9030"
MySQL:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=fiesug4Oji0be1ohk6oyae3EomaNg8uc
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=Aix5Airohth1ma3oSh3meHiijei6Usah
安装并启动
docker-compose up -d
安装dinky
经过发现这个版本的镜像,重启后不会报错.相对稳定
docker run -itd --network=nginx_ngu_network \
--name dinky dinkydocker/dinky-standalone-server:1.1.0-flink1.18
dinky配置
docker exec -it dinky bash
cd extends/flink1.19
wget https://repo1.maven.org/maven2/com/starrocks/flink-connector-starrocks/1.2.10_flink-1.19/flink-connector-starrocks-1.2.10_flink-1.19.jar
# 此处用的版本和flink中引用的不一样.但是经过测试,是完全兼容的,可放心食用
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.1/flink-sql-connector-mysql-cdc-2.4.1.jar
# 至此, dinky中的jar包配置完成
# 退出容器
exit
# 重启dinky
docker restart dinky
访问dinky http://localhost:8888
用户名: admin 密码 :dinky123!@#
登录后尽快修改密码
dinky控制台配置单独安装的flink
新建任务并提交即可
任务示例
CREATE TABLE IF NOT EXISTS `orders1_src` (
`order_id` BIGINT NOT NULL,
`dt` DATE NULL,
`user_id` INT NULL,
`good_id` INT NULL,
PRIMARY KEY (`order_id`) NOT ENFORCED
)
with
(
'username' = 'root',
'password' = 'taedohlahsoow7ebiath6Iaf2uokagah',
'database-name' = 'tmp_test',
'table-name' = 'orders1',
'connector' = 'mysql-cdc',
'hostname' = '172.20.0.10',
'port' = '3306',
'server-time-zone' = 'Asia/Shanghai',
'debezium.poll.interval.ms' = '200', -- Binlog轮询间隔(200ms)
'scan.incremental.snapshot.chunk.size' = '1000', -- 减少快照分块大小
'heartbeat.interval' = '1s' -- 心跳间隔(保活连接) .默认为0.如果设为 0,可能因连接闲置被数据库服务器关闭
);
CREATE TABLE IF NOT EXISTS `orders1_sink` (
`order_id` BIGINT NOT NULL,
`dt` DATE NULL,
`user_id` INT NULL,
`good_id` INT NULL,
`good_name` STRING NULL,
PRIMARY KEY (`order_id`) NOT ENFORCED
)
with
(
'sink.max-retries' = '10',
'password' = 'kuutooP2Daeghezi0thieyej5quiFace',
'sink.properties.strip_outer_array' = 'true',
'load-url' = '10.0.0.2:8030',
'database-name' = 'quickstart',
'jdbc-url' = 'jdbc:mysql://10.0.0.2:9030',
'sink.properties.format' = 'json',
'username' = 'root',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'starrocks',
'table-name' = 'orders1',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.partial_update' = 'true',
'sink.properties.columns' = 'order_id,dt,user_id,good_id',
-- 关键参数:控制写入频率
'sink.buffer-flush.interval-ms' = '1000', -- 1秒刷写一次
'sink.buffer-flush.max-rows' = '64000', -- 每批次最多64000行
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true'
);
insert into
orders1_sink (order_id, dt, user_id, good_id)
select
s.order_id,
s.dt,
s.user_id,
s.good_id
from
orders1_src s;
遇到的问题记录
1. dink提交任务,无异常,也没有执行成功
首选在dinky提交任务,因为直观简单. 如果遇到提交任务后,无异常,也没有执行成功的问题排查.在flink的sql-clent.sh中运行调试,会看到对应的错误日志
2. 如果选用的mysql镜像是mariadb:11.7.2,需要设置时区和binlog
-
设置时区+8
-
设置binlog
-
cd /etc/mysql/mariadb.conf.d cat > 61-binlog.cnf << 'EOF' [mysqld] # 启用二进制日志 log_bin = mysql-bin # 设置二进制日志格式为 ROW binlog_format = ROW # 设置服务器ID(主从复制需要) server_id = 1 EOF -
退出容器,并且重启即可
docker restart mariadb
-
其他
停止所有的flink, 慎用
jps -l | grep -i flink | awk '{print $1}' | xargs kill -9
MySQL相关
-- 确认 binlog_format 已改为 ROW
SHOW VARIABLES LIKE 'binlog_format';
--是否开启binlog
SHOW VARIABLES LIKE 'log_bin';
-- 查看时区
SELECT @@global.time_zone, @@session.time_zone;
不要直接修改my.cnf , 从容器中在/etc/mysql看到my.cnf来自于my.cnf -> /etc/alternatives/my.cnf
配置在mariadb.conf.d下新增或修改
Flink-CDC同步多表关联数据优化
场景9张表关联, 主表数据3万不到.其他表多次关联, 其他关联表数据很少. 但是9次关联之后,一次完整同步需要耗时30分钟
环境
StarRocks版本
SHOW VARIABLES LIKE '%version%';
| Variable_name | Value | 说明 |
|---|---|---|
| version | 5.1.0 | 表示当前 StarRocks 的 SQL 语法兼容性 基于 MySQL 5.1.0 协议 |
| version_comment | StarRocks version 2.5.10 | StarRocks 实际的数据库版本号 |
flink版本
flink --version
Version: 1.18.1
dinky版本
1.1.0
MySQL版本
|Variable_name|Value|
|-------------|-----|
|innodb_version|5.7.24|
|protocol_version|10|
|slave_type_conversions||
|version|10.2.21-MariaDB-log|
|version_comment|MariaDB Server|
|version_compile_machine|x86_64|
|version_compile_os|Linux|
|version_malloc_library|system|
|version_ssl_library|YaSSL 2.4.4|
|wsrep_patch_version|wsrep_25.23|
docker-compose部署调试环境
mdbook使用记录
使得mdbook在发布后支持数学公式
1. 根目录的book.toml中注释或者删除math相关的所有
2. 项目根目录与src平级的目录处, 新建theme目录,theme目录新建文件head.hbs,这个文件会被mdbook自动加载。
mdbook内容如下:
<script>
window.MathJax = {
tex: {inlineMath: [['$', '$'], ['\\(', '\\)']]}
};
</script>
<script src="https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js"></script>
<script>
function renderMath() {
if (window.MathJax) {
MathJax.typesetPromise();
}
}
// 页面初次加载
document.addEventListener("DOMContentLoaded", renderMath);
// mdBook 切换章节时
document.addEventListener("DOMContentLoaded", () => {
const observer = new MutationObserver(renderMath);
observer.observe(document.querySelector("#content"), { childList: true, subtree: true });
});
</script>
mdbook 结合github action发布太慢优化
观察发现,github每次打包都要重新便宜mdbook,导致花费时间太长,所以优化mdbook.yml直接用已经打包的二进制包 样例:
name: Deploy mdBook site to Pages
on:
push:
branches: ["master"]
workflow_dispatch:
permissions:
contents: read
pages: write
id-token: write
concurrency:
group: "pages"
cancel-in-progress: false
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
# 直接下载你打好的 Linux 版 mdBook
- name: Install mdBook (Chinese search fork)
run: |
curl -L -o mdbook https://github.com/zhangyinyuan/mdBook/releases/download/auto-build/mdbook-linux
chmod +x mdbook
sudo mv mdbook /usr/local/bin/
- name: Setup Pages
id: pages
uses: actions/configure-pages@v5
- name: Build with mdBook
run: mdbook build
- name: Upload artifact
uses: actions/upload-pages-artifact@v3
with:
path: ./book # 注意自己大号包之后的文件夹的名称, 由book.toml文件中的build-dir属性决定
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
needs: build
steps:
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
clash-verge
自动切换
配置好之后,设置规则,即可

网络设置
虚拟网卡模式TUN
启用DNS覆写
调整DNS相关属性
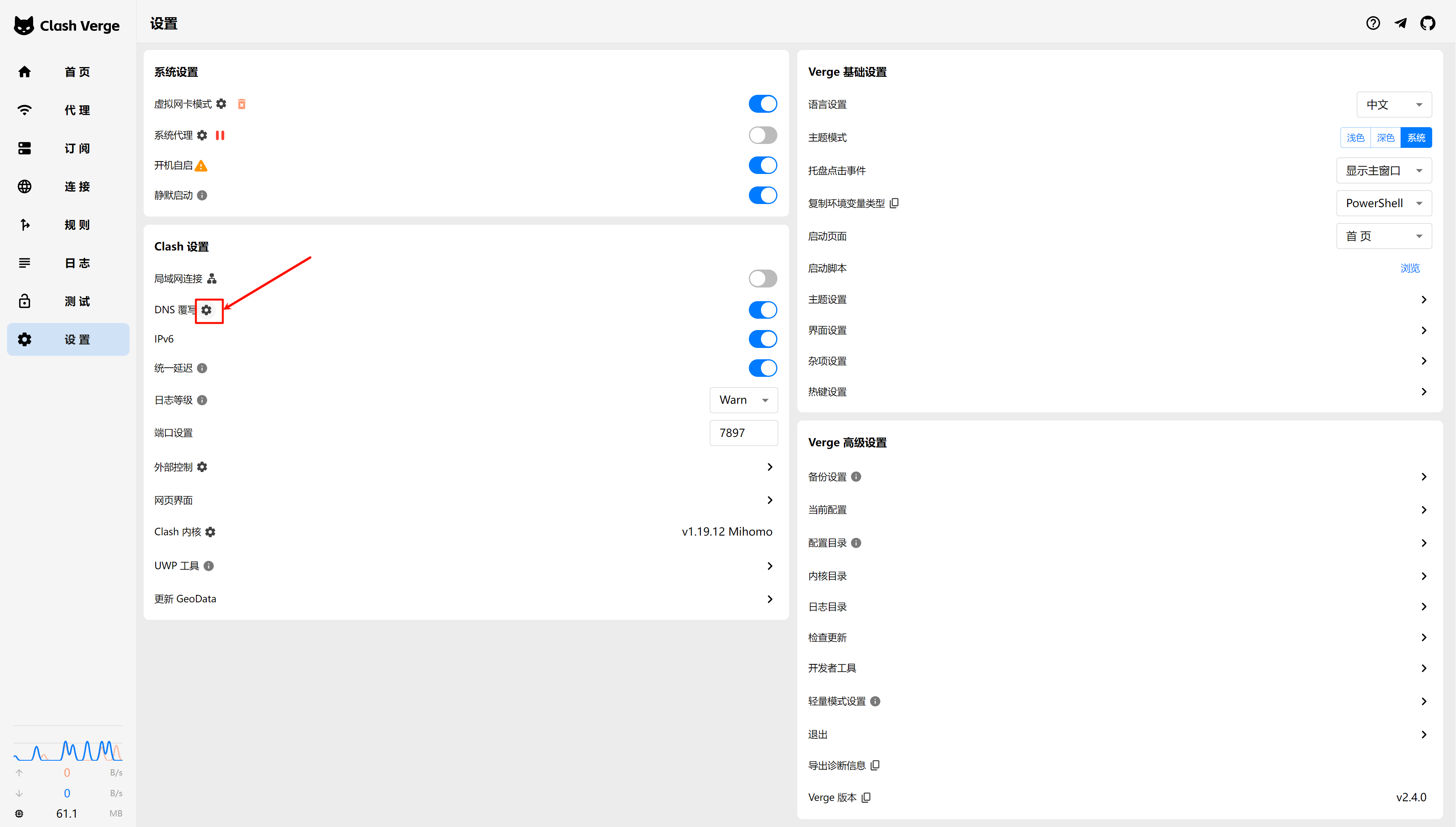
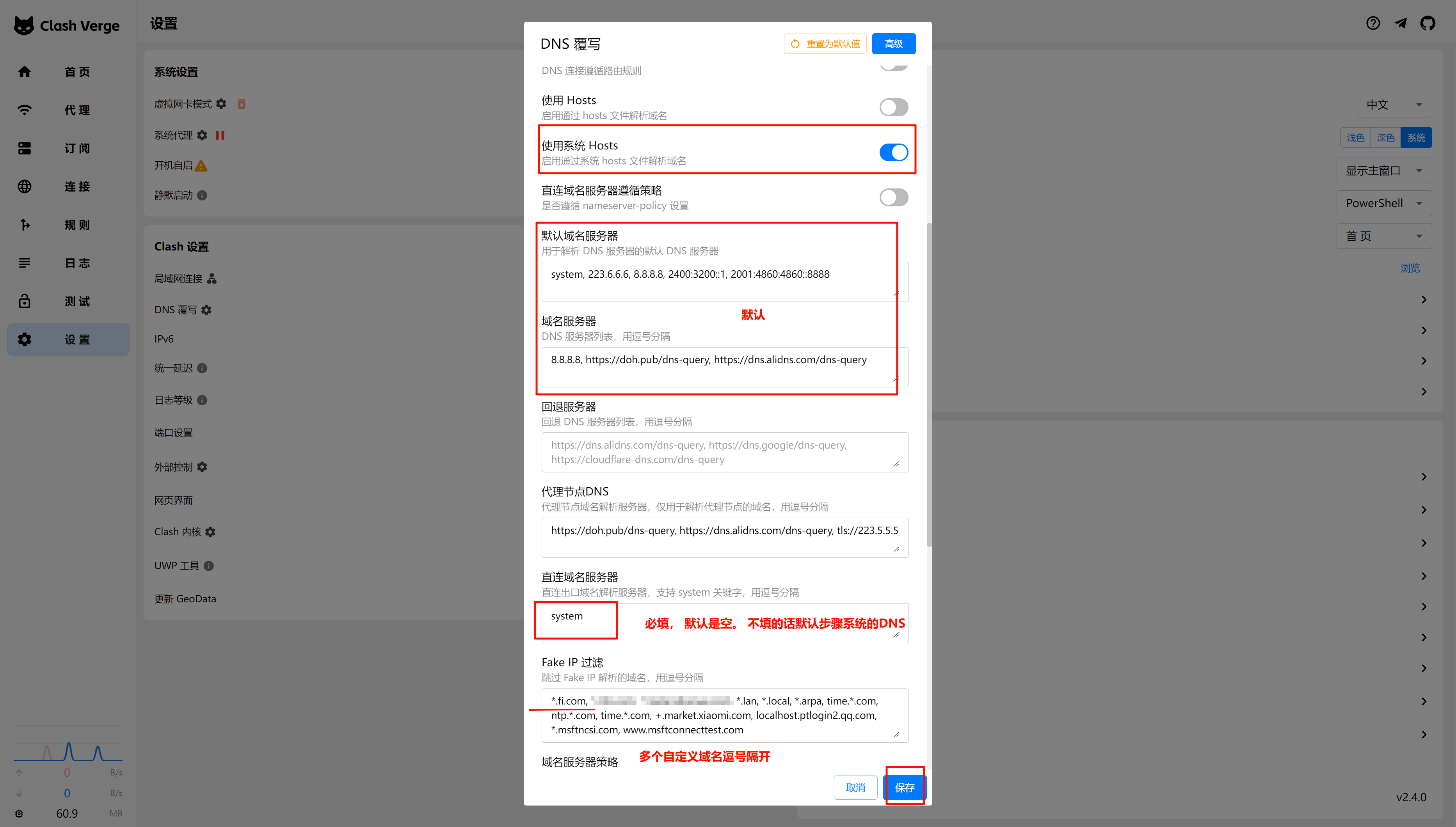
禁止idea粘贴文本自动格式化
禁止自动去掉末尾的空格(原汁原味保存)
禁用EditorConfig
保存动作禁止格式化